The News
This week DigitalOcean added a free CDN option for retrieving public files on their Spaces product. If you haven't heard about it, Spaces is like AWS S3 but Digital Ocean instead. You use the same tools as you use for S3, like s3cmd. It's super easy to use in the admin control panel and you can do all sorts of neat and nifty things via the web. And the documentation about how to use setup and use s3cmd is very good.
If we just focus on the CDN functionality, it's just a URL to a distributed resource that can be reached and retrieved faster because the server you get it from is hopefully geographically as near to you as possible. That's also what AWS CloudFront, Akamai CDN, and KeyCDN do. However, what you can do with the likes of KeyCDN is that you can have what's called a "pull zone". You basically host the files on your regular (aka. "origin server") and the CDN will automatically pick it up from there.
With DigitalOcean Spaces CDN...
1) GET https://myspace.nyc3.cdn.digitaloceanspaces.com/myfile.jpg
2) CDN doesn't have it because it's never been requested before
3) CDN does GET https://myspace.nyc3.digitaloceanspaces.com and serves it
4) If it didn't exist on https://myspace.nyc3.digitaloceanspaces.com the client gets a 404 Not Found.
With KeyCDN CDN...
1) GET https://myzone.kxcdn.com/myfile.jpg
2) CDN doesn't have it because it's never been requested before
3) CDN does GET https://www.mypersonalnginx.example.com/myfile.jpg and serves it
4) If it didn't exist https://www.mypersonalnginx.example.com/myfile.jpg the client gets a 404 Not Found
The critical differences is that with DigitalOcean Spaces CDN, it won't go and check your web server. On your web server it's not enough to have the files on disk. You have to upload them to the Spaces.
That's often not a problem because disks are not something you want to rely on anyway. It's better to store all files to something like Spaces or S3 and then feel free to just throw away the web server and recreate it. However, it's an important distinction.
On Performance
It's hard to measure these things but when shopping around for a CDN provider/solution you want to make sure you get one that is fast and reliable. There are lots of sites that compare CDNs, like cdnperf.com but I often find that they either don't have the CDN I could chose or there's something else weird about the comparison.
So I set up a test using Hyperping.io. I created a URL that uses KeyCDN and a URL that uses DigitalOcean Spaces CDN. It's the same 32KB image JPEG. Then, I created two monitors on Hyperping, both from San Francisco, New York, London, Frankfurt, Mumbai, São Paulo and Sydney.
Now they've been doing GET requests to these respective URLs for about 24h and the results so far are as follows:
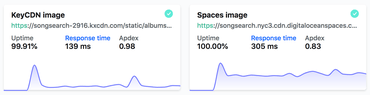
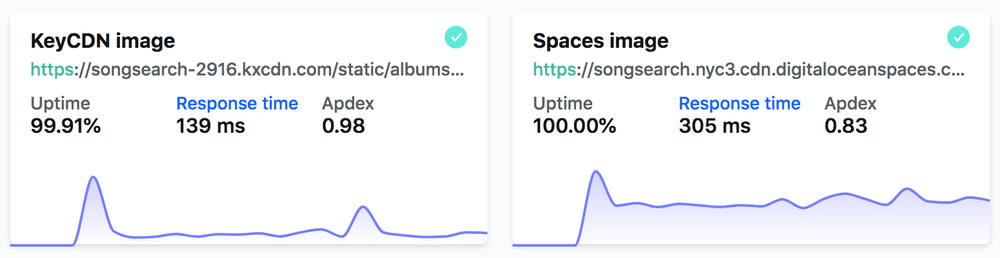
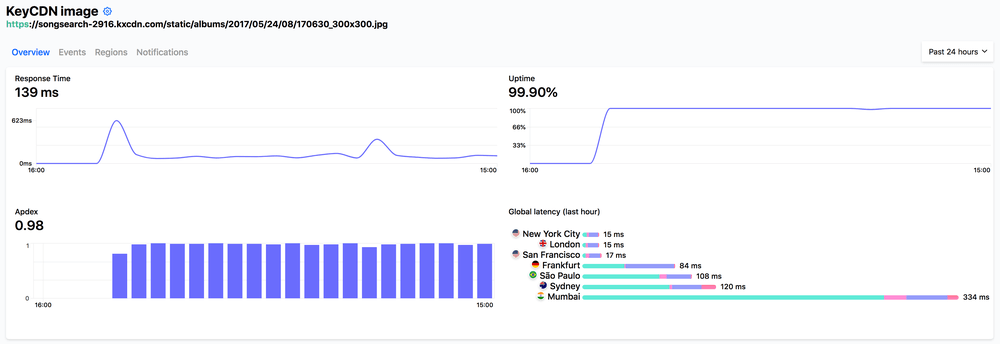
- KeyCDN: Response Time 139ms
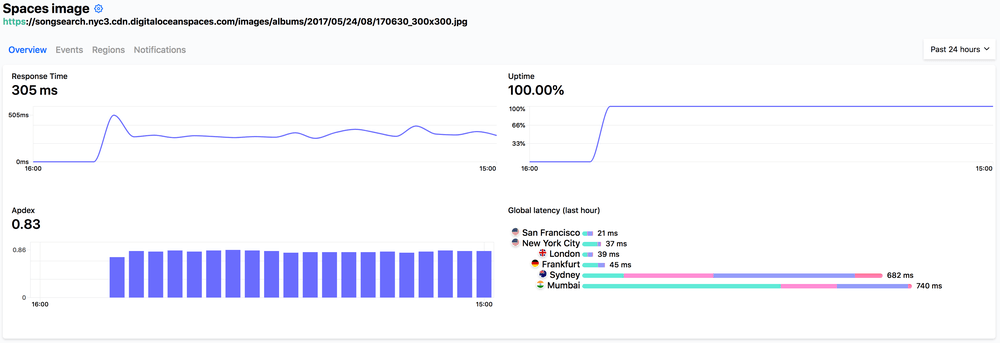
- DigitalOcean Spaces: Response Time: 305ms
I don't know how much response times are "skewed" because of the long tail of response times for Mumbai and Sydney.
But if you take an average of the times for San Francisco, New York, London and Frankfurt you get:
- KeyCDN: Average 33ms
- DigitalOcean Spaces: Average 36ms
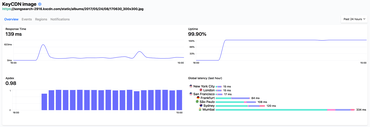
KeyCDN on Hyperping
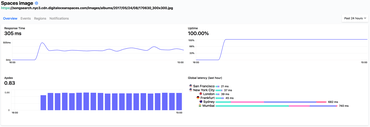
DigitalOcean Spaces on Hyperping
In Conclusion
Being able to offload all the files from disk and put them somewhere safe is an important feature. In my side project Song Search I actually, currently, host about 7GB of images (~500k files), directly on disk and it's making me nervous. I need to move them off to something like Spaces. But it's a cumbersome to have to make sure every single file generated on disk is correctly synced. Especially if post-processing is happening with the file using the local file system. (This project runs mozjpeg and guetzli on every time).
Either way, this is a non-trivial dev-ops topic with many angles and opinions. I just thought I'd share about my quick research and performance testing.
And last but not least, the difference between 20ms and 30ms isn't important if 90+% of your visitors are from US. All of these considerations depend on your context.
UPDATE - Oct 1, 2018
I'll continue to take the risk of looking like an idiot who doesn't understand networks and the science of data analysis.
I wrote a Python script which downloads random images from each CDN URL. You leave it running for a long time and hopefully the median will start to even out and be less affected by your own network saturation.
I ran it on my laptop; from South Carolina, USA:
DOMAIN MEDIAN MEAN
songsearch.nyc3.cdn.digitaloceanspaces.com 0.140s 0.335s
songsearch-2916.kxcdn.com 0.165s 0.250s
2,705 iterations.
And my colleague Mathieu ran it; from Barcelona, Spain:
DOMAIN MEDIAN MEAN
songsearch.nyc3.cdn.digitaloceanspaces.com 1.027s 1.168s
songsearch-2916.kxcdn.com 0.574s 0.648s
134 iterations.
And my colleague Ethan ran it; from New York City, USA:
DOMAIN MEDIAN MEAN
songsearch.nyc3.cdn.digitaloceanspaces.com 0.335s 0.595s
songsearch-2916.kxcdn.com 0.066s 0.076s
122 iterations.
I think that if you're in Barcelona you're so far away from the nearest edge location that the latency is "king of the difference". Mathieu found the KeyCDN median download times to be almost twices as good!
If you're in New York, where I suspect DigitalOcean has an edge location and I know KeyCDN has one the latency probably matters less and what matters more is the speed of the CDN web servers. In Ethan's case (only 122 measurement points) the median for KeyCDN is almost five times better! Not sure what that means but it definitely raises thoughts about how this actually matters a lot.
Also, if you're in Barcelona you would definitely want to download the little JPEGs half a second faster if you could.





{kind=link}
{kind=link}