I have an app that does a lot of Redis queries. It all runs in AWS with ElastiCache Redis. Due to the nature of the app, it stores really large hash tables in Redis. The application then depends on querying Redis for these. The question is; What is the best configuration possible for the fastest service possible?
Note! Last month I wrote Fastest cache backend possible for Django which looked at comparing Redis against Memcache. Might be an interesting read too if you're not sold on Redis.
Options
All options are variations on the compressor, serializer and parser which are things you can override in django-redis. All have an effect on the performance. Even compression, for if the number of bytes between Redis and the application is smaller, then it should have better network throughput.
Without further ado, here are the variations:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/0',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
"json": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/1',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"SERIALIZER": "django_redis.serializers.json.JSONSerializer",
}
},
"ujson": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/2',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"SERIALIZER": "fastestcache.ujson_serializer.UJSONSerializer",
}
},
"msgpack": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/3',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"SERIALIZER": "django_redis.serializers.msgpack.MSGPackSerializer",
}
},
"hires": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/4',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"PARSER_CLASS": "redis.connection.HiredisParser",
}
},
"zlib": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/5',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"COMPRESSOR": "django_redis.compressors.zlib.ZlibCompressor",
}
},
"lzma": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": config('REDIS_LOCATION', 'redis://127.0.0.1:6379') + '/6',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"COMPRESSOR": "django_redis.compressors.lzma.LzmaCompressor"
}
},
}
As you can see, they each have a variation on the OPTIONS.PARSER_CLASS, OPTIONS.SERIALIZER or OPTIONS.COMPRESSOR.
The default configuration is to use redis-py and to pickle the Python objects to a bytestring. Pickling in Python is pretty fast but it has the disadvantage that it's Python specific so you can't have a Ruby application reading the same Redis database.
The Experiment
Note how I have one LOCATION per configuration. That's crucial for the sake of testing. That way one database is all JSON and another is all gzip etc.
What the benchmark does is that it measures how long it takes to READ a specific key (called benchmarking). Then, once it's done that it appends that time to the previous value (or [] if it was the first time). And lastly it writes that list back into the database. That way, towards the end you have 1 key whose value looks something like this: [0.013103008270263672, 0.003879070281982422, 0.009411096572875977, 0.0009970664978027344, 0.0002830028533935547, ..... MANY MORE ....].
Towards the end, each of these lists are pretty big. About 500 to 1,000 depending on the benchmark run.
In the experiment I used wrk to basically bombard the Django server on the URL /random (which makes a measurement with a random configuration). On the EC2 experiment node, it finalizes around 1,300 requests per second which is a decent number for an application that does a fair amount of writes.
The way I run the Django server is with uwsgi like this:
uwsgi --http :8000 --wsgi-file fastestcache/wsgi.py --master --processes 4 --threads 2
And the wrk command like this:
wrk -d30s "http://127.0.0.1:8000/random"
(that, by default, runs 2 threads on 10 connections)
At the end of starting the benchmarking, I open http://localhost:8000/summary which spits out a table and some simple charts.
An Important Quirk
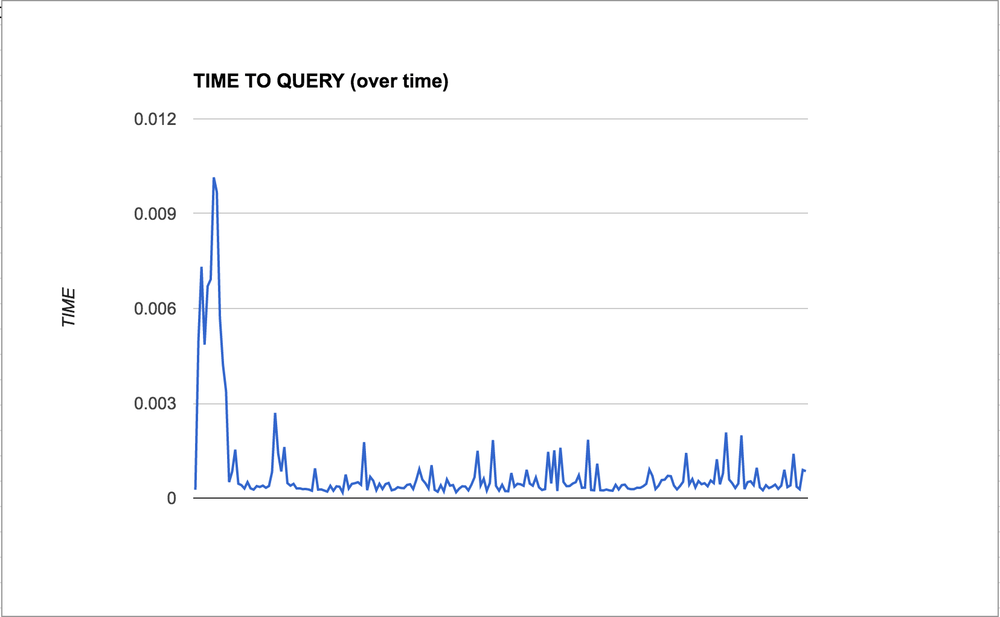
One thing I noticed when I started was that the final numbers' average was very different from the medians. That would indicate that there are spikes. The graph on the right shows the times put into that huge Python list for the default configuration for the first 200 measurements. Note that there are little spikes but generally quite flat over time once it gets past the beginning.
Sure enough, it turns out that in almost all configurations, the time it takes to make the query in the beginning is almost order of magnitude slower than the times once the benchmark has started running for a while.
So in the test code you'll see that it chops off the first 10 times. Perhaps it should be more than 10. After all, if you don't like the spikes you can simply look at the median as the best source of conclusive truth.
The Code
The benchmarking code is here. Please be aware that this is quite rough. I'm sure there are many things that can be improved, but I'm not sure I'm going to keep this around.
The Equipment
The ElastiCache Redis I used was a cache.m3.xlarge (13 GiB, High network performance) with 0 shards and 1 node and no multi-zone enabled.
The EC2 node was a m4.xlarge Ubuntu 16.04 64-bit (4 vCPUs and 16 GiB RAM with High network performance).
Both the Redis and the EC2 were run in us-west-1c (North Virginia).
The Results
Here are the results! Sorry if it looks terrible on mobile devices.
root@ip-172-31-2-61:~# wrk -d30s "http://127.0.0.1:8000/random" && curl "http://127.0.0.1:8000/summary"
Running 30s test @ http://127.0.0.1:8000/random
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.19ms 6.32ms 60.14ms 80.12%
Req/Sec 583.94 205.60 1.34k 76.50%
34902 requests in 30.03s, 2.59MB read
Requests/sec: 1162.12
Transfer/sec: 88.23KB
TIMES AVERAGE MEDIAN STDDEV
json 2629 2.596ms 2.159ms 1.969ms
msgpack 3889 1.531ms 0.830ms 1.855ms
lzma 1799 2.001ms 1.261ms 2.067ms
default 3849 1.529ms 0.894ms 1.716ms
zlib 3211 1.622ms 0.898ms 1.881ms
ujson 3715 1.668ms 0.979ms 1.894ms
hires 3791 1.531ms 0.879ms 1.800ms
Best Averages (shorter better)
###############################################################################
██████████████████████████████████████████████████████████████ 2.596 json
█████████████████████████████████████ 1.531 msgpack
████████████████████████████████████████████████ 2.001 lzma
█████████████████████████████████████ 1.529 default
███████████████████████████████████████ 1.622 zlib
████████████████████████████████████████ 1.668 ujson
█████████████████████████████████████ 1.531 hires
Best Medians (shorter better)
###############################################################################
███████████████████████████████████████████████████████████████ 2.159 json
████████████████████████ 0.830 msgpack
████████████████████████████████████ 1.261 lzma
██████████████████████████ 0.894 default
██████████████████████████ 0.898 zlib
████████████████████████████ 0.979 ujson
█████████████████████████ 0.879 hires
Size of Data Saved (shorter better)
###############################################################################
█████████████████████████████████████████████████████████████████ 60K json
██████████████████████████████████████ 35K msgpack
████ 4K lzma
█████████████████████████████████████ 35K default
█████████ 9K zlib
████████████████████████████████████████████████████ 48K ujson
█████████████████████████████████████ 34K hires
Discussion Points
- There is very little difference once you avoid the
jsonserialized one. msgpackis the fastest by a tiny margin. I prefer median over average because it's more important how it over a long period of time.- The
default(which ispickle) is fast too. lzmaandzlibcompress the strings very well. Worth thinking about the fact thatzlibis a very universal tool and makes the app "Python agnostic".- You probably don't want to use the
jsonserializer. It's fat and slow. - Using
hiresmakes very little difference. That's a bummer. - Considering how useful
zlibis (since you can fit so much much more data in your Redis) it's impressive that it's so fast too! - I quite like
zlib. If you use that on thepickleserializer you're able to save ~3.5 times as much data. - Laugh all you want but until today I had never heard of
lzma. So based on that odd personal fact, I'm pessmistic towards that as a compression choice.
Conclusion
This experiment has lead me to the conclusion that the best serializer is msgpack and the best compression is zlib. That is the best configuration for django-redis.
msgpack has implementation libraries for many other programming languages. Right now that doesn't matter for my application but if msgpack is both faster and more versatile (because it supports multiple languages) I conclude that to be the best serializer instead.
Comments
Thanks for this very insightful article. Have you tried using lz4 instead of zlib for compression?