UPDATE (Jan 31, 2024)
Since this was published, I've added tsx to the benchmark. The updated results, if you skip the two slowest are:
Summary
bun src/index.ts ran
4.69 ± 0.20 times faster than esrun src/index.ts
7.07 ± 0.30 times faster than tsx src/index.ts
7.24 ± 0.33 times faster than esno src/index.ts
7.40 ± 0.68 times faster than ts-node --transpileOnly src/index.ts
END OF UPDATE
From the totally unscientific bunker research lab of executing TypeScript files on the command line...
I have a very simple TypeScript app that you can run from the command line:
import { Command } from "commander";
const program = new Command();
program
.option("-d, --debug", "output extra debugging")
.option("-s, --small", "small pizza size")
.option("-p, --pizza-type <type>", "flavour of pizza");
program.parse(process.argv);
const options = program.opts();
console.log("options", options);
tsc
In the original days, there was just tsc which, when given your *.ts would create an equivalent *.js file. Remember this?:
> tsc src/index.ts
> node src/index.js
> rm src/index.js
(note, most likely you'd put "outDir": "./build", in your tsconfig.json so it creates build/index.js instead)
Works. And it checks potential faults in your TypeScript code itself. For example:
❯ tsc src/index.ts
src/index.ts:8:21 - error TS2339: Property 'length' does not exist on type 'Command'.
8 console.log(program.length);
~~~~~~
I don't know about you, but I rarely encounter these kinds of errors. If you view a .ts[x] file you're working on in Zed or VS Code it's already red and has squiggly lines.
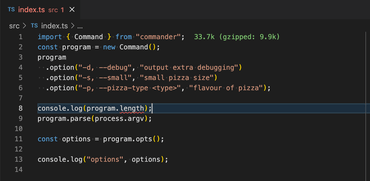
Sure, you'll make sure, one last time in your CI scripts that there are no TypeScript errors like this:
ts-node
ts-node, from that I gather is the "original gangster" of abstractions on top of TypeScript. It works quite similarly to tsc except you don't bother dumping the .js file to disk to then run it with node.
tsc src/index.ts && node src/index.js is the same as ts-node src/index.ts
It also has error checking, by default, when you run it. It can look like this:
❯ ts-node src/index.ts
/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:859
return new TSError(diagnosticText, diagnosticCodes, diagnostics);
^
TSError: ⨯ Unable to compile TypeScript:
src/index.ts:8:21 - error TS2339: Property 'length' does not exist on type 'Command'.
8 console.log(program.length);
~~~~~~
at createTSError (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:859:12)
at reportTSError (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:863:19)
at getOutput (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:1077:36)
at Object.compile (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:1433:41)
at Module.m._compile (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:1617:30)
at Module._extensions..js (node:internal/modules/cjs/loader:1310:10)
at Object.require.extensions.<computed> [as .ts] (/Users/peterbe/dev/JAVASCRIPT/esrun-tsnode-esno/node_modules/ts-node/src/index.ts:1621:12)
at Module.load (node:internal/modules/cjs/loader:1119:32)
at Function.Module._load (node:internal/modules/cjs/loader:960:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12) {
diagnosticCodes: [ 2339 ]
}
But, suppose you don't really want those TypeScript errors right now. Suppose you are confident it doesn't error, then you want it to run as fast as possible. That's where ts-node --transpileOnly src/index.ts comes in. It's significantly faster. If you compare ts-node src/index.ts with ts-node --transpileOnly src/index.ts:
❯ hyperfine "ts-node src/index.ts" "ts-node --transpileOnly src/index.ts"
Benchmark 1: ts-node src/index.ts
Time (mean ± σ): 990.7 ms ± 68.5 ms [User: 1955.5 ms, System: 124.7 ms]
Range (min … max): 916.5 ms … 1124.7 ms 10 runs
Benchmark 2: ts-node --transpileOnly src/index.ts
Time (mean ± σ): 301.5 ms ± 10.6 ms [User: 286.7 ms, System: 44.4 ms]
Range (min … max): 283.0 ms … 313.9 ms 10 runs
Summary
ts-node --transpileOnly src/index.ts ran
3.29 ± 0.25 times faster than ts-node src/index.ts
In other words, ts-node --transpileOnly src/index.ts is 3 times faster than ts-node src/index.ts
esno and @digitak/esrun
@digitak/esrun and esno are improvements to ts-node, as far as I can understand, are improvements on ts-node that can only run. I.e. you still have to use tsc --noEmit in your CI scripts. But they're supposedly both faster than ts-node --transpileOnly:
❯ hyperfine "ts-node --transpileOnly src/index.ts" "esrun src/index.ts" "esno src/index.ts"
Benchmark 1: ts-node --transpileOnly src/index.ts
Time (mean ± σ): 291.8 ms ± 10.5 ms [User: 276.9 ms, System: 43.9 ms]
Range (min … max): 280.3 ms … 309.1 ms 10 runs
Benchmark 2: esrun src/index.ts
Time (mean ± σ): 226.4 ms ± 6.0 ms [User: 187.9 ms, System: 42.8 ms]
Range (min … max): 216.8 ms … 237.5 ms 13 runs
Benchmark 3: esno src/index.ts
Time (mean ± σ): 237.2 ms ± 3.9 ms [User: 222.8 ms, System: 45.2 ms]
Range (min … max): 229.6 ms … 244.6 ms 12 runs
Summary
esrun src/index.ts ran
1.05 ± 0.03 times faster than esno src/index.ts
1.29 ± 0.06 times faster than ts-node --transpileOnly src/index.ts
In other words, esrun is 1.05e times faster than esno and 1.29 times faster than ts-node --transpileOnly.
But given that I quite like running npm run dev to use ts-node without the --transpileOnly error for realtime TypeScript errors in the console that runs a dev server, I don't know if it's worth it.
(BONUS) bun
If you haven't heard of bun in the Node ecosystem, you've been living under a rock. It's kinda like deno but trying to appeal to regular Node projects from the ground up and it does things like bun install so much faster than npm install that you wonder if it even ran. It too can run in transpile-only mode and just execute the TypeScript code as if it was JavaScript directly. And it's fast!
Because ts-node --transpileOnly is a bit of a "standard", let's compare the two:
❯ hyperfine "ts-node --transpileOnly src/index.ts" "bun src/index.ts"
Benchmark 1: ts-node --transpileOnly src/index.ts
Time (mean ± σ): 286.9 ms ± 6.9 ms [User: 274.4 ms, System: 41.6 ms]
Range (min … max): 272.0 ms … 295.8 ms 10 runs
Benchmark 2: bun src/index.ts
Time (mean ± σ): 40.3 ms ± 2.0 ms [User: 29.5 ms, System: 9.9 ms]
Range (min … max): 36.5 ms … 47.1 ms 60 runs
Summary
bun src/index.ts ran
7.12 ± 0.40 times faster than ts-node --transpileOnly src/index.ts
Wow! Given its hype, I'm not surprised bun is 7 times faster than ts-node --transpileOnly.
But admittedly, not all programs work seamlessly in bun like my sample app did this in example.
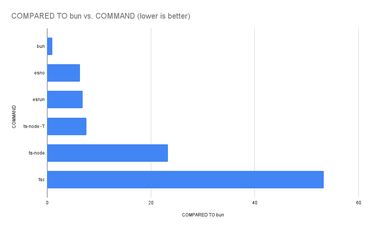
Here's the complete result comparing all of them:
❯ hyperfine "tsc src/index.ts && node src/index.js" "ts-node src/index.ts" "ts-node --transpileOnly src/index.ts" "esrun src/index.ts" "esno src/index.ts" "bun src/index.ts"
Benchmark 1: tsc src/index.ts && node src/index.js
Time (mean ± σ): 2.158 s ± 0.097 s [User: 5.145 s, System: 0.201 s]
Range (min … max): 2.032 s … 2.276 s 10 runs
Benchmark 2: ts-node src/index.ts
Time (mean ± σ): 942.0 ms ± 40.6 ms [User: 1877.2 ms, System: 115.6 ms]
Range (min … max): 907.4 ms … 1012.4 ms 10 runs
Benchmark 3: ts-node --transpileOnly src/index.ts
Time (mean ± σ): 307.1 ms ± 14.4 ms [User: 291.0 ms, System: 45.3 ms]
Range (min … max): 283.1 ms … 329.0 ms 10 runs
Benchmark 4: esrun src/index.ts
Time (mean ± σ): 276.4 ms ± 121.0 ms [User: 198.9 ms, System: 45.7 ms]
Range (min … max): 212.2 ms … 619.2 ms 10 runs
Warning: The first benchmarking run for this command was significantly slower than the rest (619.2 ms). This could be caused by (filesystem) caches that were not filled until after the first run. You should consider using the '--warmup' option to fill those caches before the actual benchmark. Alternatively, use the '--prepare' option to clear the caches before each timing run.
Benchmark 5: esno src/index.ts
Time (mean ± σ): 257.7 ms ± 14.3 ms [User: 238.3 ms, System: 48.0 ms]
Range (min … max): 238.8 ms … 282.0 ms 10 runs
Benchmark 6: bun src/index.ts
Time (mean ± σ): 40.5 ms ± 1.6 ms [User: 29.9 ms, System: 9.8 ms]
Range (min … max): 36.4 ms … 44.8 ms 62 runs
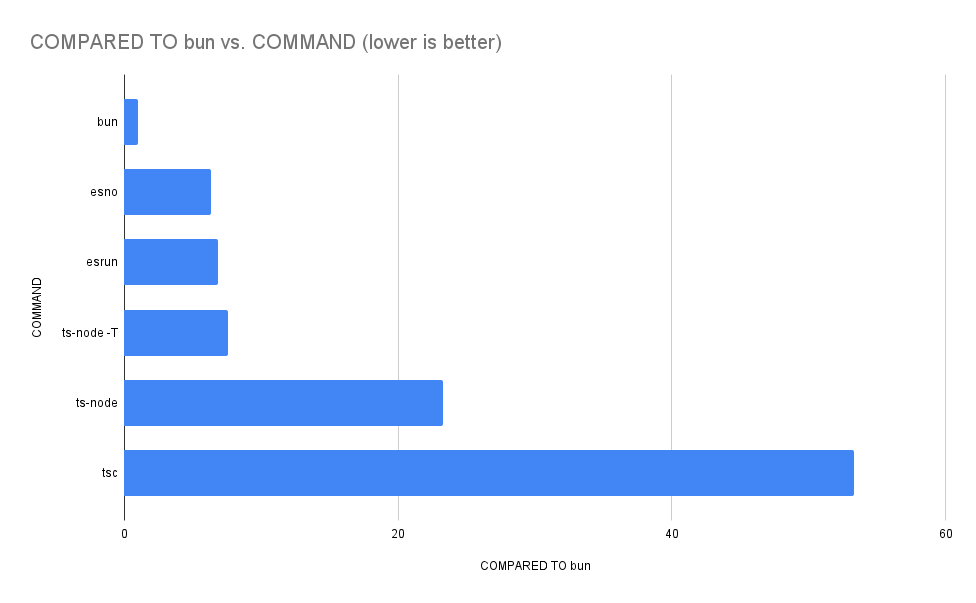
Summary
bun src/index.ts ran
6.36 ± 0.44 times faster than esno src/index.ts
6.82 ± 3.00 times faster than esrun src/index.ts
7.58 ± 0.47 times faster than ts-node --transpileOnly src/index.ts
23.26 ± 1.38 times faster than ts-node src/index.ts
53.29 ± 3.23 times faster than tsc src/index.ts && node src/index.js
Conclusion
Perhaps you can ignore bun. It might best fastest, but it's also "weirdest". It usually works great in small and simple apps and especially smaller ones that just you have to maintain (if "maintain" is even a concern at all).
I don't know how to compare them in size. ts-node is built on top of acorn which is written in JavaScript. @digitak/esrun is a wrapper for esbuild (and esno is wrapper for tsx which is also on top of esbuild) which is a fast bundler written in Golang. So it's packaged as a binary in your node_modules which hopefully works between your laptop, your CI, and your Dockerfile but it's nevertheless a binary.
Given that esrun and esno isn't that much faster than ts-node and ts-node can check your TypeScript that's a bonus for ts-node.
But esbuild is an actively maintained project that seems to become stable and accepted.
As always, this was just a quick snapshot of an unrealistic app that is less than 10 lines of TypeScript code. I'd love to hear more about what kind of results people are getting comparing the above tool when you apply it on much larger projects that have more complex tsconfig.json for things like JSX.