I can't believe I didn't know about this until today! When you're viewing a file in a repo on GitHub.com you can press l (lowercase L) and it will show a dialog to jump to a specific line.
Demo:
(please, ignore the code, it's ancient)
I can't believe I didn't know about this until today! When you're viewing a file in a repo on GitHub.com you can press l (lowercase L) and it will show a dialog to jump to a specific line.
Demo:
(please, ignore the code, it's ancient)
If you go to https://github.com/peterbe it lists the most recent blog posts here on my blog. The page is rebuilt every hour using GitHub Actions. This blog post is about how I built that, so that you can build something just like it.
In case you don't have access or it's quicker to look at a picture, this is what it looks like:
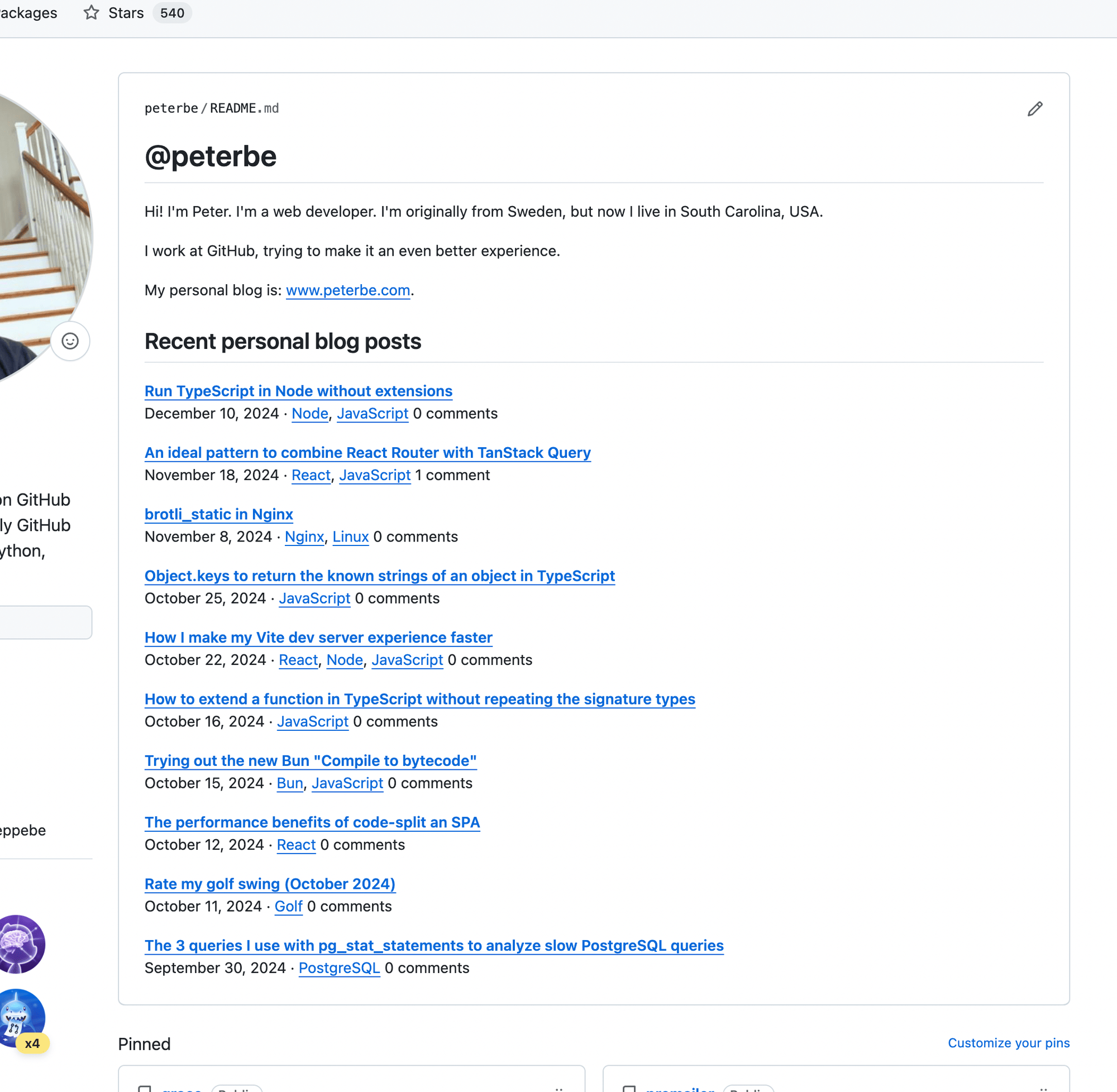
The way GitHub profiles work is you create a GitHub repo that is in the same name as your username. In my case, my username is peterbe, and the repo is thus called peterbe. So, it's named https://github.com/peterbe/peterbe. It has to be a public repo for this to work.
In that repo you have a README.md and mine looks like this: https://github.com/peterbe/peterbe/blob/main/README.md?plain=1 If you look carefully, the Markdown in that README.md contains:
<!-- blog posts -->
...
<!-- /blog posts -->
By default, HTML comments work in GitHub-flavored Markdown just like they do in HTML.
Then, I have a Node script that finds that inside the file and replaces its content with a list of Markdown links.
Truncated! Read the rest by clicking the link below.
tl;dr You can search GitHub issues specifically only in the title by adding in:title.
Suppose you go to a GitHub repository's Issue list. If you search, it will find issues that match your search in any field. For example:
Finding 70 issues by dialog
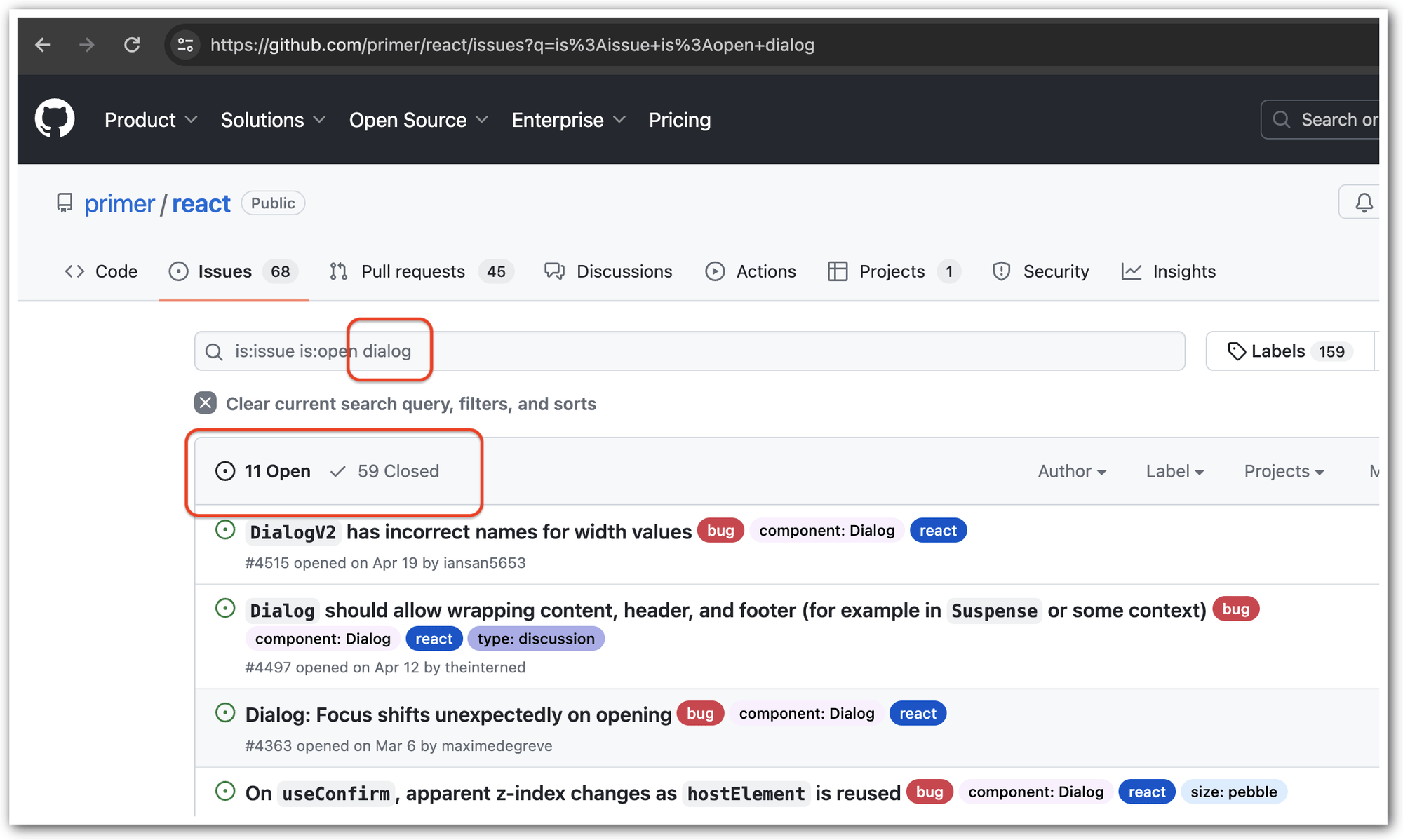
Now, add in:title to the search input:
Truncated! Read the rest by clicking the link below.
tl;dr git restore -- .
I can't believe I didn't know this! Maybe, at one point, I did, but, since forgotten.
You're in a Git repo and you have edited 4 files and run git status and see this:
❯ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: four.txt
modified: one.txt
modified: three.txt
modified: two.txt
no changes added to commit (use "git add" and/or "git commit -a")
Suppose you realize; "Oh no! I didn't mean to make those changes in three.txt" You can restore that file by mentioning it by name:
Truncated! Read the rest by clicking the link below.
Suppose you have a GitHub Action workflow that does some computation and a possible outcome is that file comes into existence. How do you run a follow-up step based on whether a file was created?
tl;dr
- name: Is file created?
if: ${{ hashFiles('test.txt') != '' }}
run: echo "File exists"
Technically, there's no wrong way, but an alternative might be to rely on exit codes. This would work.
- name: Check if file was created
run: |
if [ -f test.txt ]; then
echo "File exists"
exit 1
else
echo "File does not exist"
fi
- name: Did the last step fail?
if: ${{ failure() }}
run: echo "Last step failed, so file must have maybe been created"
The problem with this is that not only leaves a red ❌ in the workflow logs, but it could also lead to false positives. For example, if the step that might create a file is non-trivial, you don't want to lump the creation of the file with a possible bug in your code.
What I needed this for was a complex script that was executed to find broken links in a web app. If there were broken links, only then do I want to file a new issue about that. If the script failed for some reason, you want to know that and work on fixing whatever its bug might be. It looked like this:
- name: Run broken link check
run: |
script/check-links.js broken_links.md
- name: Create issue from file
if: ${{ hashFiles('broken_links.md') != '' }}
uses: peter-evans/create-issue-from-file@433e51abf769039ee20ba1293a088ca19d573b7f
with:
token: ${{ env.GITHUB_TOKEN }}
title: More than one zero broken links found
content-filepath: ./broken_links.md
repository: ${{ env.REPORT_REPOSITORY }}
labels: ${{ env.REPORT_LABEL }}
That script/check-links.js script is given an argument which is the name of the file to write to if it did indeed find any broken links. If there were any, it generates a snippet of Markdown about them which is the body of filed new issue.
To be confident this works, I created a dummy workflow in a test repo to test. It looks like this: .github/workflows/maybe-fail.yml
Inside a step in a GitHub Action, I want to run a script, and depending on the outcome of that, maybe do some more things. Essentially, if the script fails, I want to print some extra user-friendly messages, but the whole Action should still fail with the same exit code.
In pseudo-code, this is what I want to achieve:
exit_code = that_other_script()
if exit_code > 0:
print("Extra message if it failed")
exit(exit_code)
So here's how to do that with bash:
# If it's not the default, make it so that it proceeds even if
# any one line exits non-zero
set +e
./script/update-internal-links.js --check
exit_code=$?
if [ $exit_code != 0 ]; then
echo "Extra message here informing that the script failed"
exit $exit_code
fi
The origin, for me, at the moment, was that I had a GitHub Action where it calls another script that might fail. If it fails, I wanted to print out a verbose extra hint to whoever looks at the output. Steps in GitHub Action runs with set -e by default I think, meaning that if anything goes wrong in the step it leaves the step and runs those steps with if: ${{ failure() }} next.
If you've used GitHub Actions before you might be familiar with the matrix strategy. For example:
name: My workflow
jobs:
build:
strategy:
matrix:
version: [10, 12, 14, 16, 18]
steps:
- name: Set up Node ${{ matrix.node }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node }}
...
But what if you want that list of things in the matrix to be variable? For example, on rainy days you want it to be [10, 12, 14] and on sunny days you want it to be [14, 16, 18]. Or, more seriously, what if you want it to depend on how the workflow is started?
You can make a workflow run on a schedule, on pull requests, on pushes, on manual "Run workflow", or as a result on some other workflow finishing.
First, let's set up some sample on directives:
name: My workflow
on:
workflow_dispatch:
schedule:
- cron: '*/5 * * * *'
workflow_run:
workflows: ['Build and Deploy stuff']
types:
- completed
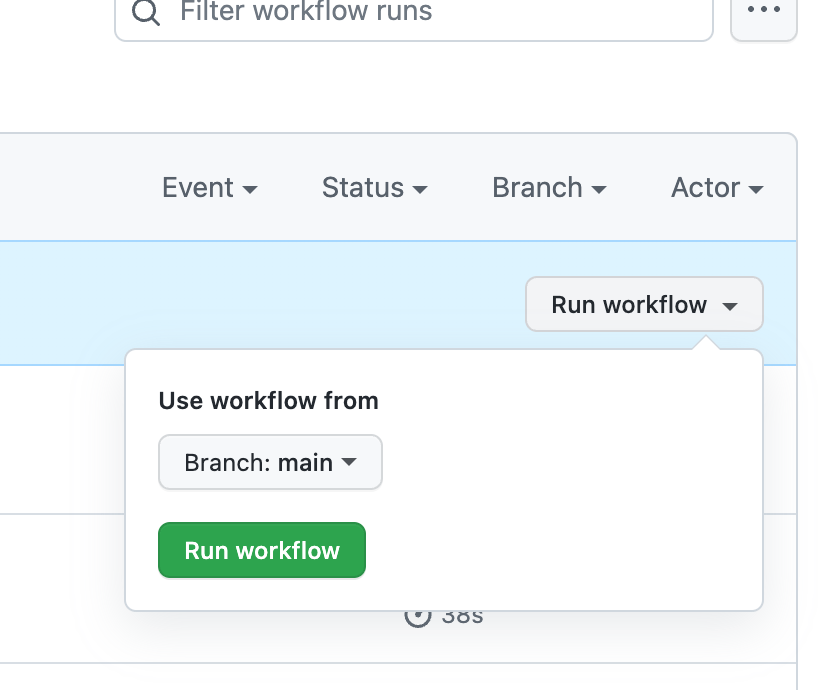
The workflow_dispatch makes it so that a button like this appears:
The schedule, in this example, means "At every 5th minute"
And workflow_run, in this example, means that it waits for another workflow, in the same repo, with name: 'Build and Deploy stuff' has finished (but not necessarily successfully)
For the sake of the demo, let's say this is the rule:
[16, 18]. [18]. Build and Deploy stuff workflow has successfully finished, you want the matrix to be [10, 12, 14, 16, 18].It's arbitrary but it could be a lot more complex than this.
What's also important to appreciate is that you could use individual steps that look something like this:
- steps:
- name: Only if started on a workflow_dispatch
if: ${{ github.event_name == 'workflow_dispatch' }}
run: echo "yes it was run because of a workflow_dispatch"
But the rest of the workflow is realistically a lot more complex with many steps and you don't want to have to sprinkle the line if: ${{ github.event_name == 'workflow_dispatch' }} into every single step.
The solution to avoiding repetition is to use a job that depends on another job. We'll have a job that figures out the array for the matrix and another job that uses that.
First we inject a job that looks like this:
jobs:
matrix_maker:
runs-on: ubuntu-latest
outputs:
matrix: ${{ steps.set-matrix.outputs.result }}
steps:
- uses: actions/github-script@v6
id: set-matrix
with:
script: |
if (context.eventName === "workflow_dispatch") {
return [18]
}
if (context.eventName === "schedule") {
return [16, 18]
}
if (context.eventName === "workflow_run") {
if (context.payload.workflow_run.conclusion === "success") {
return [10, 12, 14, 16, 18]
}
throw new Error(`It was a workflow_run but not success ('${context.payload.workflow_run.conclusion}')`)
}
throw new Error("Unable to find a reason")
- name: Debug output
run: echo "${{ steps.set-matrix.outputs.result }}"
Now we can write the "meat" of the workflow that uses this output:
build:
needs: matrix_maker
strategy:
matrix:
version: ${{ fromJSON(needs.matrix_maker.outputs.matrix) }}
steps:
- name: Set up Node ${{ matrix.version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.version }}
Combined, the entire thing can look like this:
name: My workflow
on:
workflow_dispatch:
schedule:
- cron: '*/5 * * * *'
workflow_run:
workflows: ['Build and Deploy stuff']
types:
- completed
jobs:
matrix_maker:
runs-on: ubuntu-latest
outputs:
matrix: ${{ steps.set-matrix.outputs.result }}
steps:
- uses: actions/github-script@v6
id: set-matrix
with:
script: |
if (context.eventName === "workflow_dispatch") {
return [18]
}
if (context.eventName === "schedule") {
return [16, 18]
}
if (context.eventName === "workflow_run") {
if (context.payload.workflow_run.conclusion === "success") {
return [10, 12, 14, 16, 18]
}
throw new Error(`It was a workflow_run but not success ('${context.payload.workflow_run.conclusion}')`)
}
throw new Error("Unable to find a reason")
- name: Debug output
run: echo "${{ steps.set-matrix.outputs.result }}"
build:
needs: matrix_maker
strategy:
matrix:
version: ${{ fromJSON(needs.matrix_maker.outputs.matrix) }}
steps:
- name: Set up Node ${{ matrix.version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.version }}
I've extrapolated this demo from a more complex one at work. (this is my defense for typos and why it might fail if you verbatim copy-n-paste this). The bare bones are there for you to build on.
In this demo, I've used actions/github-script with JavaScript, because it's convenient and you don't need do to things like actions/checkout and npm ci if you want this to be a standalone Node script. Hopefully you can see that this is just a start and the sky's the limit.
Thanks to fellow GitHub Hubber @joshmgross for the tips and help!
Also, check out Tips and tricks to make you a GitHub Actions power-user
tl;dr
- name: Only if auto-merge is enabled
if: ${{ github.event.pull_request.auto_merge }}
run: echo "Auto-merge IS ENABLED"
- name: Only if auto-merge is NOT enabled
if: ${{ !github.event.pull_request.auto_merge }}
run: echo "Auto-merge is NOT enabled"
The use case that I needed was that I have a workflow that does a bunch of things that aren't really critical to test the PR, but they also take a long time. In particular, every pull request deploys a "preview environment" so you get a "staging" site for each pull request. Well, if you know with confidence that you're not going to be clicking around on that preview/staging site, why bother deploying it (again)?
Also, a lot of PRs get the "Auto-merge" enabled because whoever pressed that button knows that as long as it builds OK, it's ready to merge in.
What's cool about the if: statements above is that they will work in all of these cases too:
on:
workflow_dispatch:
pull_request:
push:
branches:
- main
I.e. if this runs because it was a push to main the line ${{ !github.event.pull_request.auto_merge }} will resolve to truthy. Same if you use the workflow dispatch from workflow_dispatch.
Auto-merge is a fantastic GitHub Actions feature. You first need to set up some branch protections and then, as soon as you've created the PR you can press the "Enable auto-merge (squash)". It will ("Squash and merge") merge the PR as soon as all branch protection checks succeeded. Neat.
But what if you have a workflow that is made up of half critical and half not-so-important stuff. In particular, what if there's stuff in the workflow that is really slow and you don't want to wait. One example is that you might have a build-and-deploy workflow where you've decided that the "build" part of that is a required check, but the (slow) deployment is just a nice-to-have. Here's an example of that:
name: Build and Deploy stuff
on:
workflow_dispatch:
pull_request:
permissions:
contents: read
jobs:
build-stuff:
runs-on: ubuntu-latest
steps:
- name: Slight delay
run: sleep 5
deploy-stuff:
needs: build-stuff
runs-on: ubuntu-latest
steps:
- name: Do something
run: sleep 26
It's a bit artificial but perhaps you can see beyond that. What you can do is set up a required status check, as a branch protection, just for the build-stuff job.
Note how the job is made up of build-stuff and deploy-stuff, where the latter depends on the first. Now set up branch protection purely based on the build-stuff. This option should appear as you start typing buil there in the "Status checks that are required." section of Branch protections.
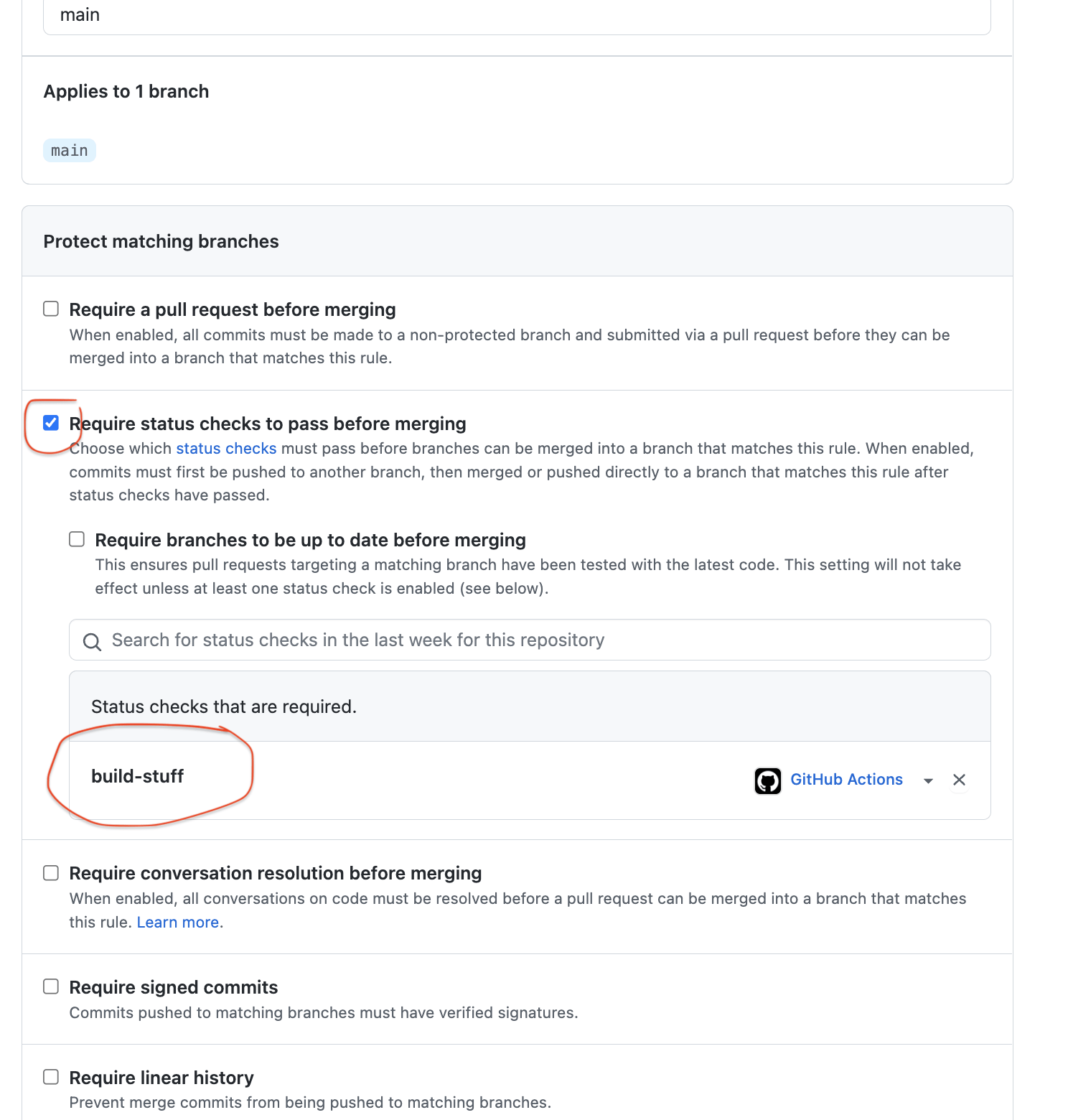
Now, when the PR is created it immediately starts working on that build-stuff job. While that's running you press the "Enable auto-merge (squash)" button:

What will happen is that as soon as the build-stuff job (technically the full name becomes "Build and Deploy stuff / build-stuff") goes green, the PR is auto-merged. But the next (dependent) job deploy-stuff now starts so even if the PR is merged you still have an ongoing workflow job running. Note the little orange dot (instead of the green checkmark).
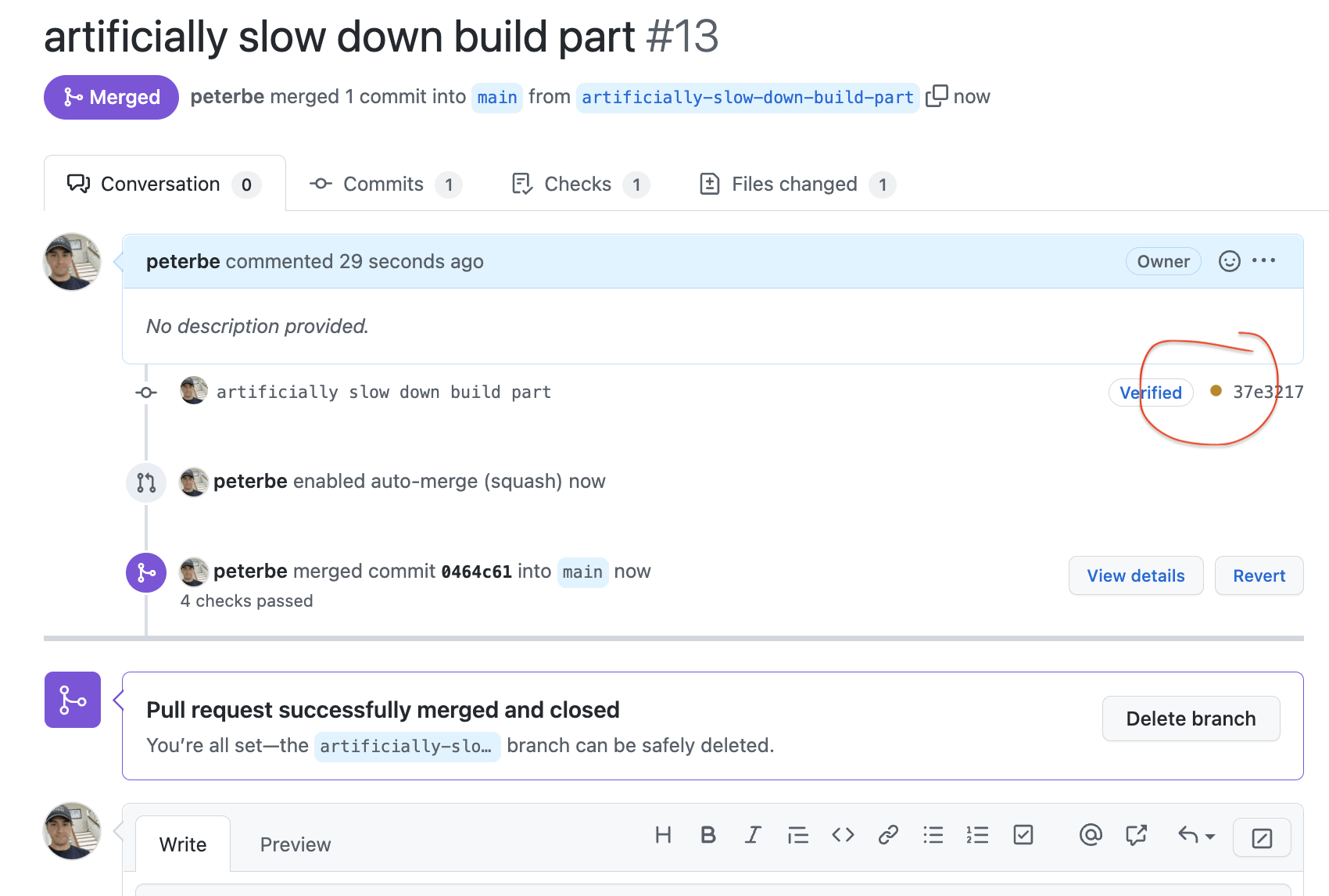
It's quite an advanced pattern and perhaps you don't have the use case yet, but it's good to know it's possible. What our use case at work was, was that we use auto-merge a lot in automation and our complete workflow depended on a slow step that is actually conditional (and a bit slow). So we didn't want the auto-merge to be delayed because of something that might be slow and might also turn out to not be necessary.
tl;dr; docsQL is a web app for analyzing lots of Markdown content files with SQL queries.
Sample instance based on MDN's open source content.
When I worked on the code for MDN in 2019-2021 I often found that I needed to understand the content better to debug or test or just find a sample page that uses some feature. I ended up writing a lot of one-off Python scripts that would traverse the repository files just to do some quick lookup that was too complex for grep. Eventually, I built a prototype called "Traits DB" which was powered by an in-browser SQL engine called alasql. Then in 2021, I joined GitHub to work on GitHub Docs and here there are lots of Markdown files too that trigger different features based on various front-matter keys.
docsQL does two things:
.md files into a docs.json file which can be queried The analyzing portion has a killer feature in that you can write your own plugins tailored specifically to your project. Your project might use some quirks that are unique. In GitHub Docs, for example, we use something called "LiquidJS" which is like a pre-Markdown processing to do things like versioning. So I can write a custom JavaScript plugin that extends data you get from reading in the front-matter.
Here's an example plugin:
const regex = /💩/g;
export default function countCocoIceMentions({ data, content }) {
const inTitle = (data.title.match(regex) || []).length;
const inBody = (content.match(regex) || []).length;
return {
chocolateIcecreamMentions: inTitle + inBody,
};
}
Now, if you add that to your project, you'll be able to run:
SELECT title, chocolateIcecreamMentions FROM ?
WHERE chocolateIcecreamMentions > 0
ORDER BY 2 DESC LIMIT 15
It's up to you. One important fact to keep in mind is that not everyone speaks SQL fluently. And even if you're somewhat confident with SQL, it might not be obvious how this particular engine works or what the fields are. (Mind you, there's a "Help" which shows you all fields and a collection of sample queries).
But it's really intuitive to extend an already written SQL query. So if someone shares their query, it's easy to just extend it. For example, your colleague might share a URL with an SQL query in the query string, but you want to change the sort order so you just edit DESC for ASC.
I would recommend that any team that has a project with a bunch of Markdown files, add docsql as a dependency somewhere, have it build with your directory of Markdown files, and then publish the docsql/out/ directory as a static web page which you can host on Netlify or GitHub Pages.
This way, your team gets a centralized place where team members can share URLs with each other that has queries in it. When someone shares one of these, they get added to your "Saved queries" and you can extend them from there to add to your own list.
The project is here: github.com/peterbe/docsql and it's MIT licensed. The analyzing part is all Node. It's a CLI that is able to dynamically import other .mjs files based on scanning the directory at runtime.
The front-end is a NextJS static build which uses Mantine for the React UI components.
You can install it npx like this:
npx docsql /path/to/my/markdown/files
But if you want to control it a bit better you can simply add it to your own Node project with: npm save docsql or yarn add docsql.
First of all, it's a very new project. My initial goal was to get the basics working. A lot of edges have been left rough. Especially in areas of installation, performance, and SQL editor. Please come and help out if you see something. In particular, if you tried to set it up but found it hard, we can work together to either improve the documentation to fix some scripts that would help the next person.
For feature requests and bug reports use: https://github.com/peterbe/docsql/issues/new
Or just comment here on the blog post.