tl;dr; Redis is 16 times faster at reading these JSON blobs.
In Song Search when you've found a song, it loads some affiliate links to Amazon.com. (In case you're curious it's earning me lower double-digit dollars per month). To avoid overloading the Amazon Affiliate Product API, after I've queried their API, I store that result in my own database along with some metadata. Then, the next time someone views that song page, it can read from my local database. With me so far?
The other caveat is that you can't store these lookups locally too long since prices change and/or results change. So if my own stored result is older than a couple of hundred days, I delete it and fetch from the network again. My current implementation uses PostgreSQL (via the Django ORM) to store this stuff. The model looks like this:
class AmazonAffiliateLookup(models.Model, TotalCountMixin):
song = models.ForeignKey(Song, on_delete=models.CASCADE)
matches = JSONField(null=True)
search_index = models.CharField(max_length=100, null=True)
lookup_seconds = models.FloatField(null=True)
created = models.DateTimeField(auto_now_add=True, db_index=True)
modified = models.DateTimeField(auto_now=True)
At the moment this database table is 3GB on disk.
Then, I thought, why not use Redis for this. Then I can use Redis's "natural" expiration by simply setting as expiry time when I store it and then I don't have to worry about cleaning up old stuff at all.
The way I'm using Redis in this project is as a/the cache backend and I have it configured like this:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": REDIS_URL,
"TIMEOUT": config("CACHE_TIMEOUT", 500),
"KEY_PREFIX": config("CACHE_KEY_PREFIX", ""),
"OPTIONS": {
"COMPRESSOR": "django_redis.compressors.zlib.ZlibCompressor",
"SERIALIZER": "django_redis.serializers.msgpack.MSGPackSerializer",
},
}
}
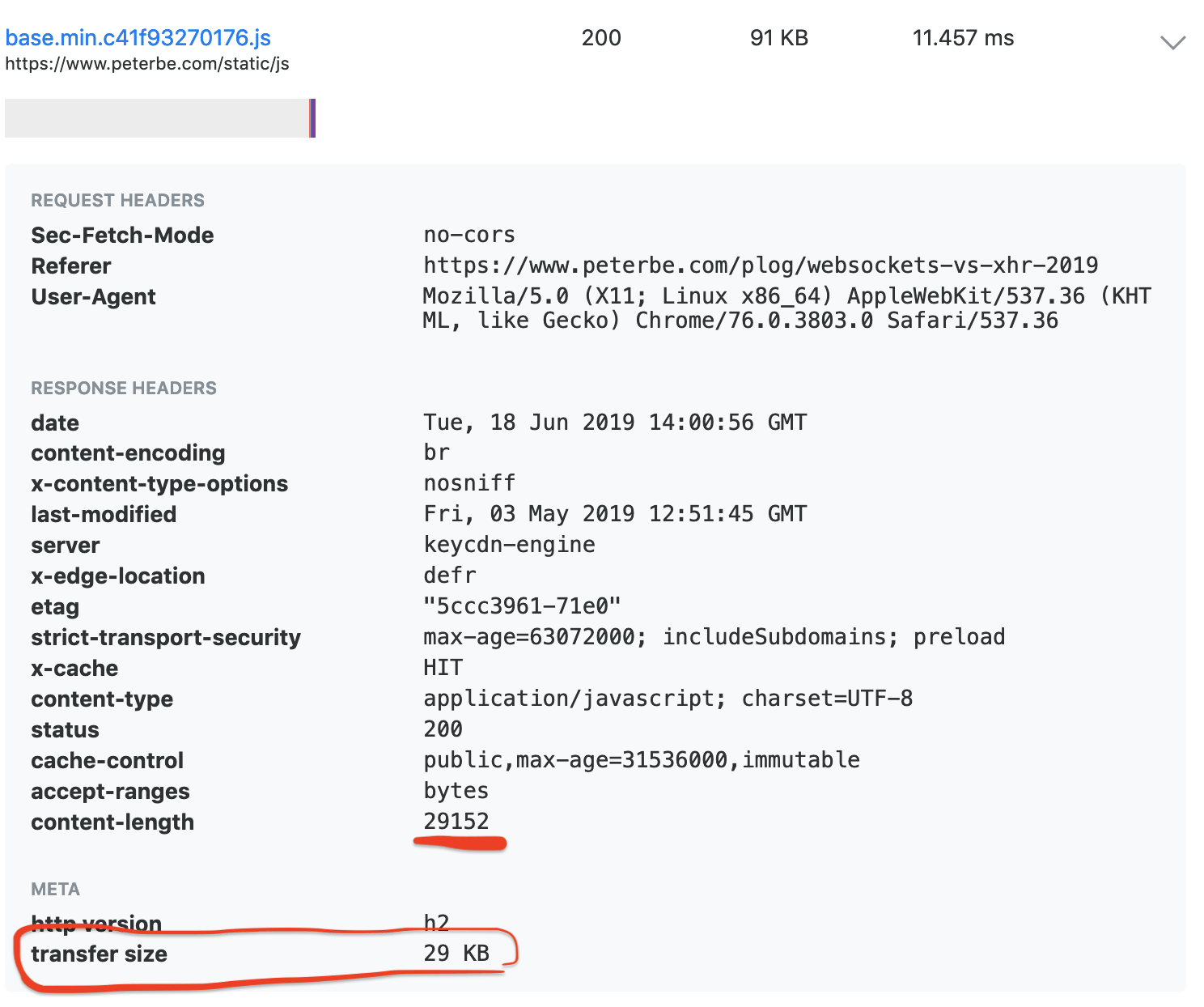
The speed difference
Perhaps unrealistic but I'm doing all this testing here on my MacBook Pro. The connection to Postgres (version 11.4) and Redis (3.2.1) are both on localhost.
Reads
The reads are the most important because hopefully, they happen 10x more than writes as several people can benefit from previous saves.
I changed my code so that it would do a read from both databases and if it was found in both, write down their time in a log file which I'll later summarize. Results are as follows:
PG: median: 8.66ms mean : 11.18ms stdev : 19.48ms Redis: median: 0.53ms mean : 0.84ms stdev : 2.26ms (310 measurements)
It means, when focussing on the median, Redis is 16 times faster than PostgreSQL at reading these JSON blobs.
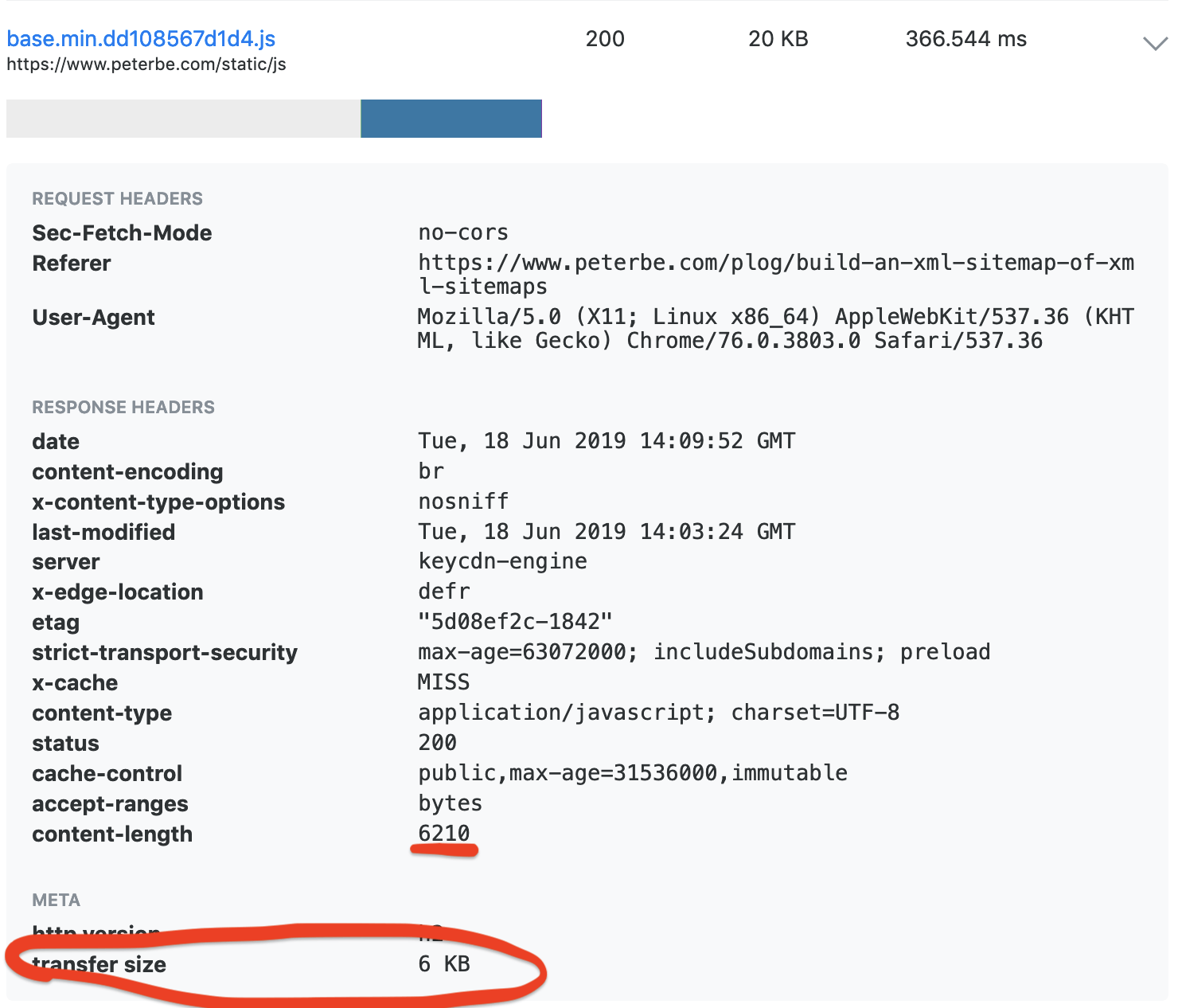
Writes
The writes are less important but due to the synchronous nature of my Django, the unlucky user who triggers a look up that I didn't have, will have to wait for the write before the XHR request can be completed. However, when this happens, the remote network call to the Amazon Product API is bound to be much slower. Results are as follows:
PG: median: 8.59ms mean : 8.58ms stdev : 6.78ms Redis: median: 0.44ms mean : 0.49ms stdev : 0.27ms (137 measurements)
It means, when focussing on the median, Redis is 20 times faster than PostgreSQL at writing these JSON blobs.
Conclusion and discussion
First of all, I'm still a PostgreSQL fan-boy and have no intention of ceasing that. These times are made up of much more than just the individual databases. For example, the PostgreSQL speeds depend on the Django ORM code that makes the SQL and sends the query and then turns it into the model instance. I don't know what the proportions are between that and the actual bytes-from-PG's-disk times. But I'm not sure I care either. The tooling around the database is inevitable mostly and it's what matters to users.
Both Redis and PostgreSQL are persistent and survive server restarts and crashes etc. And you get so many more "batch related" features with PostgreSQL if you need them, such as being able to get a list of the last 10 rows added for some post-processing batch job.
I'm currently using Django's cache framework, with Redis as its backend, and it's a cache framework. It's not meant to be a persistent database. I like the idea that if I really have to I can just flush the cache and although detrimental to performance (temporarily) it shouldn't be a disaster. So I think what I'll do is store these JSON blobs in both databases. Yes, it means roughly 6GB of SSD storage but it also potentially means loading a LOT more into RAM on my limited server. That extra RAM usage pretty much sums of this whole blog post; of course it's faster if you can rely on RAM instead of disk. Now I just need to figure out how RAM I can afford myself for this piece and whether it's worth it.
UPDATE September 29, 2019
I experimented with an optimization of NOT turning the Django ORM query into a model instance for each record. Instead, I did this:
+from dataclasses import dataclass
+@dataclass
+class _Lookup:
+ modified: datetime.datetime
+ matches: list
...
+base_qs = base_qs.values_list("modified", "matches")
-lookup = base_qs.get(song__id=song_id)
+lookup_tuple = base_qs.get(song__id=song_id)
+lookup = _Lookup(*lookup_tuple)
print(lookup.modified)
Basically, let the SQL driver's "raw Python" content come through the Django ORM. The old difference between PostgreSQL and Redis was 16x. The new difference was 14x instead.