tl;dr; Use raven's ThreadedRequestsHTTPTransport transport class to send Google Analytics pageview trackings asynchronously to Google Analytics to collect pageviews that aren't actually browser pages.
We have an API on our Django site that was not designed from the ground up. We had a bunch of internal endpoints that were used by the website. So we simply exposed those as API endpoints that anybody can query. All we did was wrap certain parts carefully as to not expose private stuff and we wrote a simple web page where you can see a list of all the endpoints and what parameters are needed. Later we added auth-by-token.
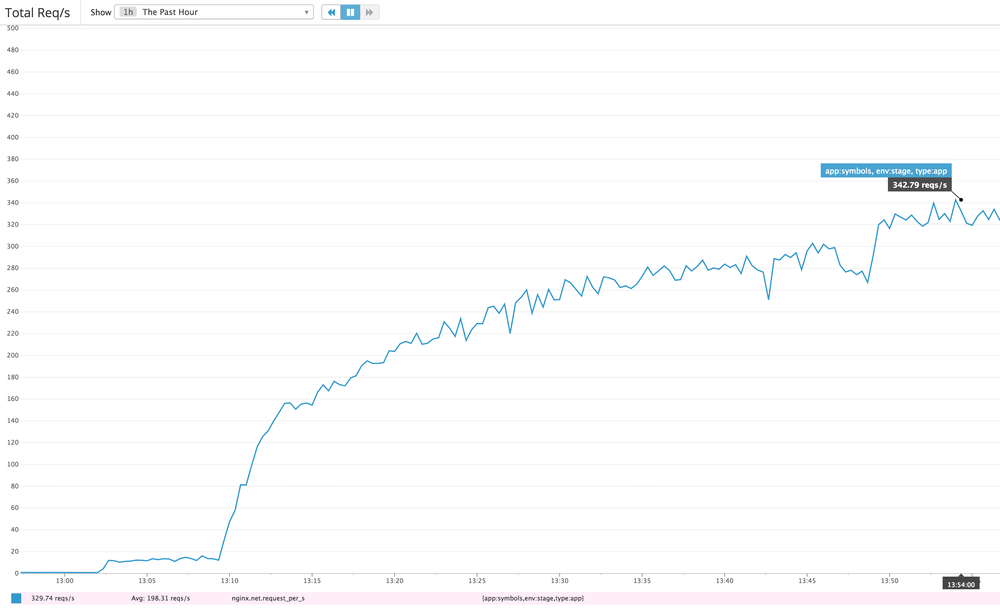
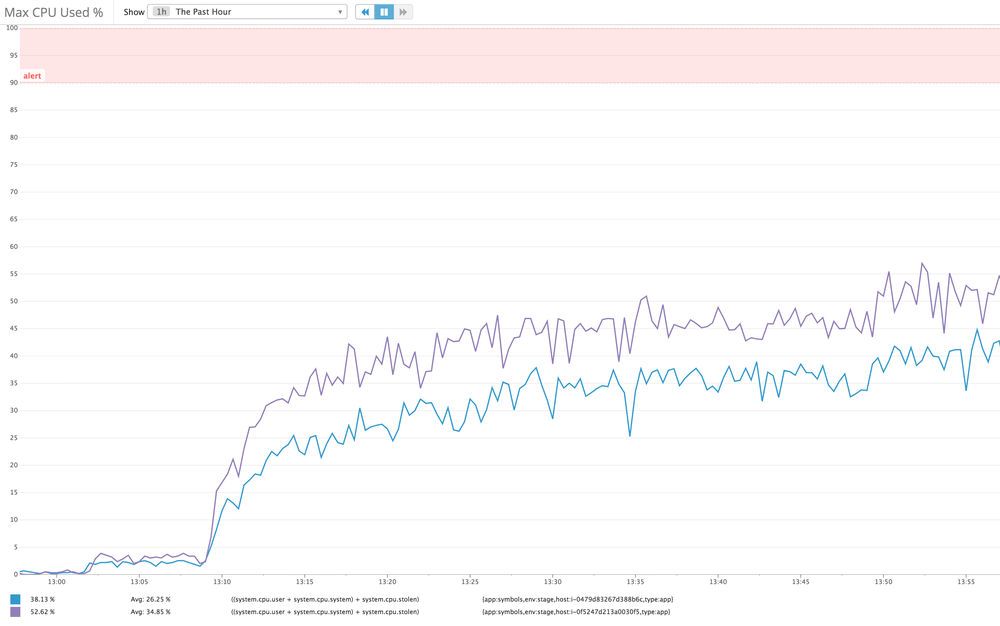
Now the problem we have is that we don't know which endpoints people use and, as equally important, which ones people don't use. If we had more stats we'd be able to confidently deprecate some (for easier maintanenace) and optimize some (to avoid resource overuse).
Our first attempt was to use statsd to collect metrics and display those with graphite. But it just didn't work out. There are just too many different "keys". Basically, each endpoint (aka URL, aka URI) is a key. And if you include the query string parameters, the number of keys just gets nuts. Statsd and graphite is better when you have about as many keys as you have fingers on one hand. For example, HTTP error codes, 200, 302, 400, 404 and 500.
Also, we already use Google Analytics to track pageviews on our website, which is basically a measure of how many people render web pages that have HTML and JavaScript. Google Analytic's UI is great and powerful. I'm sure other competing tools like Mixpanel, Piwik, Gauges, etc are great too, but Google Analytics is reliable, likely to stick around and something many people are familiar with.
So how do you simulate pageviews when you don't have JavaScript rendering? The answer; using plain HTTP POST. (HTTPS of course). And how do you prevent blocking on sending analytics without making your users have to wait? By doing it asynchronously. Either by threading or a background working message queue.
Threading or a message queue
If you have a message queue configured and confident in its running, you should probably use that. But it adds a certain element of complexity. It makes your stack more complex because now you need to maintain a consumer(s) and the central message queue thing itself. What if you don't have a message queue all set up? Use Python threading.
To do the threading, which is hard, it's always a good idea to try to stand on the shoulder of giants. Or, if you can't find a giant, find something that is mature and proven to work well over time. We found that in Raven.
Raven is the Python library, or "agent", used for Sentry, the open source error tracking software. As you can tell by the name, Raven tries to be quite agnostic of Sentry the server component. Inside it, it has a couple of good libraries for making threaded jobs whose task is to make web requests. In particuarly, the awesome ThreadedRequestsHTTPTransport. Using it basically looks like this:
import urlparse
from raven.transport.threaded_requests import ThreadedRequestsHTTPTransport
transporter = ThreadedRequestsHTTPTransport(
urlparse.urlparse('https://ssl.google-analytics.com/collect'),
timeout=5
)
params = {
...more about this later...
}
def success_cb():
print "Yay!"
def failure_cb(exception):
print "Boo :("
transporter.async_send(
params,
headers,
success_cb,
failure_cb
)
The call isn't very different from regular plain old requests.post.
About the parameters
This is probably the most exciting part and the place where you need some thought. It's non-trivial because you might need to put some careful thought into what you want to track.
Your friends is: This documentation page
There's also the Hit Builder tool where you can check that the values you are going to send make sense.
Some of the basic ones are easy:
"Protocol Version"
Just set to v=1
"Tracking ID"
That code thing you see in the regular chunk of JavaScript you put in the head, e.g tid=UA-1234-Z
"Data Source"
Optional word you call this type of traffic. We went with ds=api because we use it to measure the web API.
The user ones are a bit more tricky. Basically because you don't want to accidentally leak potentially sensitive information. We decided to keep this highly anonymized.
"Client ID"
A random UUID (version 4) number that identifies the user or the app. Not to be confused with "User ID" which is basically a string that identifies the user's session storage ID or something. Since in our case we don't have a user (unless they use an API token) we leave this to a new random UUID each time. E.g. cid=uuid.uuid4().hex This field is not optional.
"User ID"
Some string that identifies the user but doesn't reveal anything about the user. For example, we use the PostgreSQL primary key ID of the user as a string. It just means we can know if the same user make several API requests but we can never know who that user is. Google Analytics uses it to "lump" requests together. This field is optional.
Next we need to pass information about the hit and the "content". This is important. Especially the "Hit type" because this is where you make your manually server-side tracking act as if the user had clicked around on the website with a browser.
"Hit type"
Set this to t=pageview and it'll show up Google Analytics as if the user had just navigated to the URL in her browser. It's kinda weird to do this because clearly the user hasn't. Most likely she's used curl or something from the command line. So it's not really a pageview but, on our end, we have "views" in the webserver that produce information to the user. Some of it is HTML and some of it is JSON, in terms of output format, but either way they're sending us a URL and we respond with data.
"Document location URL"
The full absolute URL of that was used. E.g. https://www.example.com/page?foo=bar. So in our Django app we set this to dl=request.build_absolute_uri(). If you have a site where you might have multiple domains in use but want to collect them all under just 1 specific domain you need to set dh=example.com.
"Document Host Name" and "Document Path"
I actually don't know what the point of this is if you've already set the "Document location URL".
"Document Title"
In Google Analytics you can view your Content Drilldown by title instead of by URL path. In our case we set this to a string we know from the internal Python class that is used to make the API endpoint. dt='API (%s)'%api_model.__class__.__name__.
There are many more things you can set, such as the clients IP, the user agent, timings, exceptions. We chose to NOT include the user's IP. If people using the JavaScript version of Google Analytics can set their browser to NOT include the IP, we should respect that. Also, it's rarely interesting to see where the requests for a web API because it's often servers' curl or requests that makes the query, not the human.
Sample implementation
Going back to the code example mentioned above, let's demonstrate a fuller example:
import urlparse
from raven.transport.threaded_requests import ThreadedRequestsHTTPTransport
transporter = ThreadedRequestsHTTPTransport(
urlparse.urlparse('https://ssl.google-analytics.com/collect'),
timeout=5
)
domain = settings.GOOGLE_ANALYTICS_DOMAIN
if not domain or domain == 'auto':
domain = RequestSite(request).domain
params = {
'v': 1,
'tid': settings.GOOGLE_ANALYTICS_ID,
'dh': domain,
't': 'pageview,
'ds': 'api',
'cid': uuid.uuid4().hext,
'dp': request.path,
'dl': request.build_request_uri(),
'dt': 'API ({})'.format(model_class.__class__.__name__),
'ua': request.META.get('HTTP_USER_AGENT'),
}
def success_cb():
logger.info('Successfully informed Google Analytics (%s)', params)
def failure_cb(exception):
logger.exception(exception)
transporter.async_send(
params,
headers,
success_cb,
failure_cb
)
How to unit test this
The class we're using, ThreadedRequestsHTTPTransport has, as you might have seen, a method called async_send. There's also one, with the exact same signature, called sync_send which does the same thing but in a blocking fashion. So you could make your code look someting silly like this:
def send_tracking(page_title, request, async=True):
function = async and transporter.async_send or transporter.sync_send
function(
params,
headers,
success_cb,
failure_cb
)
And then in your tests you pass in async=False instead.
But don't do that. The code shouldn't be sub-serviant to the tests (unless it's for the sake of splitting up monster-long functions).
Instead, I recommend you mock the inner workings of that ThreadedRequestsHTTPTransport class so you can make the whole operation synchronous. For example...
import mock
from django.test import TestCase
from django.test.client import RequestFactory
from where.you.have import pageview_tracking
class TestTracking(TestCase):
@mock.patch('raven.transport.threaded_requests.AsyncWorker')
@mock.patch('requests.post')
def test_pageview_tracking(self, rpost, aw):
def mocked_queue(function, data, headers, success_cb, failure_cb):
function(data, headers, success_cb, failure_cb)
aw().queue.side_effect = mocked_queue
request = RequestFactory().get('/some/page')
with self.settings(GOOGLE_ANALYTICS_ID='XYZ-123'):
pageview_tracking('Test page', request)
print rpost.mock_calls
This is synchronous now and works great. It's not finished. You might want to write a side effect for the requests.post so you can have better control of that post. That'll also give you a chance to potentially NOT return a 200 OK and make sure that your failure_cb callback function gets called.
How to manually test this
One thing I was very curious about when I started was to see how it worked if you really ran this for reals but without polluting your real Google Analytics account. For that I built a second little web server on the side, whose address I used instead of https://ssl.google-analytics.com/collect. So, change your code so that https://ssl.google-analytics.com/collect is not hardcoded but a variable you can change locally. Change it to http://localhost:5000/ and start this little Flask server:
import time
import random
from flask import Flask, abort, request
app = Flask(__name__)
app.debug = True
@app.route("/", methods=['GET', 'POST'])
def hello():
print "- " * 40
print request.method, request.path
print "ARGS:", request.args
print "FORM:", request.form
print "DATA:", repr(request.data)
if request.args.get('sleep'):
sec = int(request.args['sleep'])
print "** Sleeping for", sec, "seconds"
time.sleep(sec)
print "** Done sleeping."
if random.randint(1, 5) == 1:
abort(500)
elif random.randint(1, 5) == 1:
time.sleep(20)
return "OK"
if __name__ == "__main__":
app.run()
Now you get an insight into what gets posted and you can pretend that it's slow to respond. Also, you can get an insight into how your app behaves when this collection destination throws a 5xx error.
How to really test it
Google Analytics is tricky to test in that they collect all the stuff they collect then they take their time to process it and it then shows up the next day as stats. But, there's a hack! You can go into your Google Analytics account and click "Real-Time" -> "Overview" and you should see hits coming in as you're testing this. Obviously you don't want to do this on your real production account, but perhaps you have a stage/dev instance you can use. Or, just be patient :)


{kind=link}