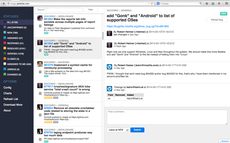
Buggy is a singe-page webapp that relies entirely on the Bugzilla Native REST API. And it works offline. Sort of. I say "sort of" because obviously without a network connection you're bound to have outdated information from the bugzilla database but at least you'll have what you had when you went offline.
When you post a comment from Buggy, the posted comment is added to an internal sync queue and if you're online it immediately processes that queue. There is, of course, always a risk that you might close a bug when you're in a tunnel or on a plane without WiFi and when you later get back online the sync fails because of some conflict.
The reason I built this was partly to scratch an itch I had ("What's the ideal way possible for me to use Bugzilla?") and also to experiment with some new techniques, namely AngularJS and localforage.
So, the way it works is:
-
You pick your favorite product and components.
-
All bugs under these products and components are downloaded and stored locally in your browser (thank you localforage).
-
When you click any bug it then proceeds to download its change history and its comments.
-
Periodically it checks each of your chosen product and components to see if new bugs or new comments have been added.
-
If you refresh your browser, all bugs are loaded from a local copy stored in your browser and in the background it downloads any new bugs or comments or changes.
-
If you enter your username and password, an auth token is stored in your browser and you can thus access secure bugs.
Pros and cons
The main advantage of Buggy compared to Bugzilla is that it's fast to navigate. You can instantly filter bugs by status(es), components and/or by searching in the bug summary.
The disadvantage of Buggy is that you can't see all fields, file new bugs or change all fields.
The code
The code is of course open source. It's available on https://github.com/peterbe/buggy and released under a MPL 2 license.
The code requires no server. It's just an HTML page with some CSS and Javascript.
Everything is done using AngularJS. It's only my second AngularJS project but this is also part of why I built this. To learn AngularJS better.
Much of the inspiration came from the CSS framework Pure and one of their sample layouts which I started with and hacked into shape.
The deployment
Because Buggy doesn't require a server, this is the very first time I've been able to deploy something entirely on CDN. Not just the images, CSS and Javascript but the main HTML page as well. Before I explain how I did that, let me explain about the make.py script.
I really wanted to use Grunt but it just didn't work for me. There are many positive things about Grunt such as the ease with which you can easily add plugins and I like how you just have one "standard" file that defines how a bunch of meta tasks should be done. However, I just couldn't get the concatenation and minification and stuff to work together. Individually each tool works fine, such as the grunt-contrib-uglify plugin but together none of them appeared to want to work. Perhaps I just required too much.
In the end I wrote a script in python that does exactly what I want for deployment. Its features are:
- Hashes in the minified and concatenated CSS and Javascript files (e.g.
vendor-8254f6b.min.js)
- Custom names for the minified and concatenated CSS and Javascript files so I can easily set far-future cache headers (e.g.
/_cache/vendor-8254f6b.min.js)
- Ability to fold all CSS minified into the HTML (since there's only one page, theres little reason to make the CSS external)
- A Git revision SHA into the HTML of the generated
./dist/index.html file
- All files in
./client/static/ copied intelligently into ./dist/static/
- Images in CSS to be given hashes so they too can have far-future cache headers
So, the way I have it set up is that, on my server, I have a it run python make.py and that generates a complete site in a ./dist/ directory. I then point Nginx to that directory and run it under http://buggy-origin.peterbe.com. Then I set up a Amazon Cloudfront distribution to that domain and then lastly I set up a CNAME for buggy.peterbe.com to point to the Cloudfront distribution.
The future
I try my best to maintain a TODO file inside the repo. That's where I write down things to come. (it's also works as a changelog) since I also use this file to write down what's been done.
One of the main features I want to add is the ability to add bugs that are outside your chosen products and components. It'll be a "fake" component called "Misc". This is for bugs outside the products and components you usually monitor and work in but perhaps bugs you've filed or been assigned to. Or just other bugs you're interested in in general.
Another major feature to work on is the ability to choose to see more fields and ability to edit these too. This will require some configuration on the individual users' behalf. For example, some people use the "Target Milestone" a lot. Some use the "Importance" a lot. So, some generic solution is needed to accomodate all these non-basic fields.
And last but not least, the Bugzilla team here at Mozilla is working on a very exciting project that allows you to register a certain list of bugs with a WebSocket and have it push to you as soon as these bugs change. That means that I won't have to periodically query bugzilla every 30 seconds if certain bugs have changed but instead get instant notifications when they do. That's going to be major! I confidently speculate that that will be implemented some time summer this year.
Give it a go. What are you waiting for? :) Go to http://buggy.peterbe.com/, pick your favorite products and components and try to use it for a week.