We use poetry in MDN Kuma. That means there's a pyproject.toml and a poetry.lock file. To add or remove dependencies, you don't touch either file in an editor. For example, to add a package:
poetry add --dev black
It changes pyproject.toml and poetry.lock for you. (Same with yarn add somelib which edits package.json and yarn.lock).
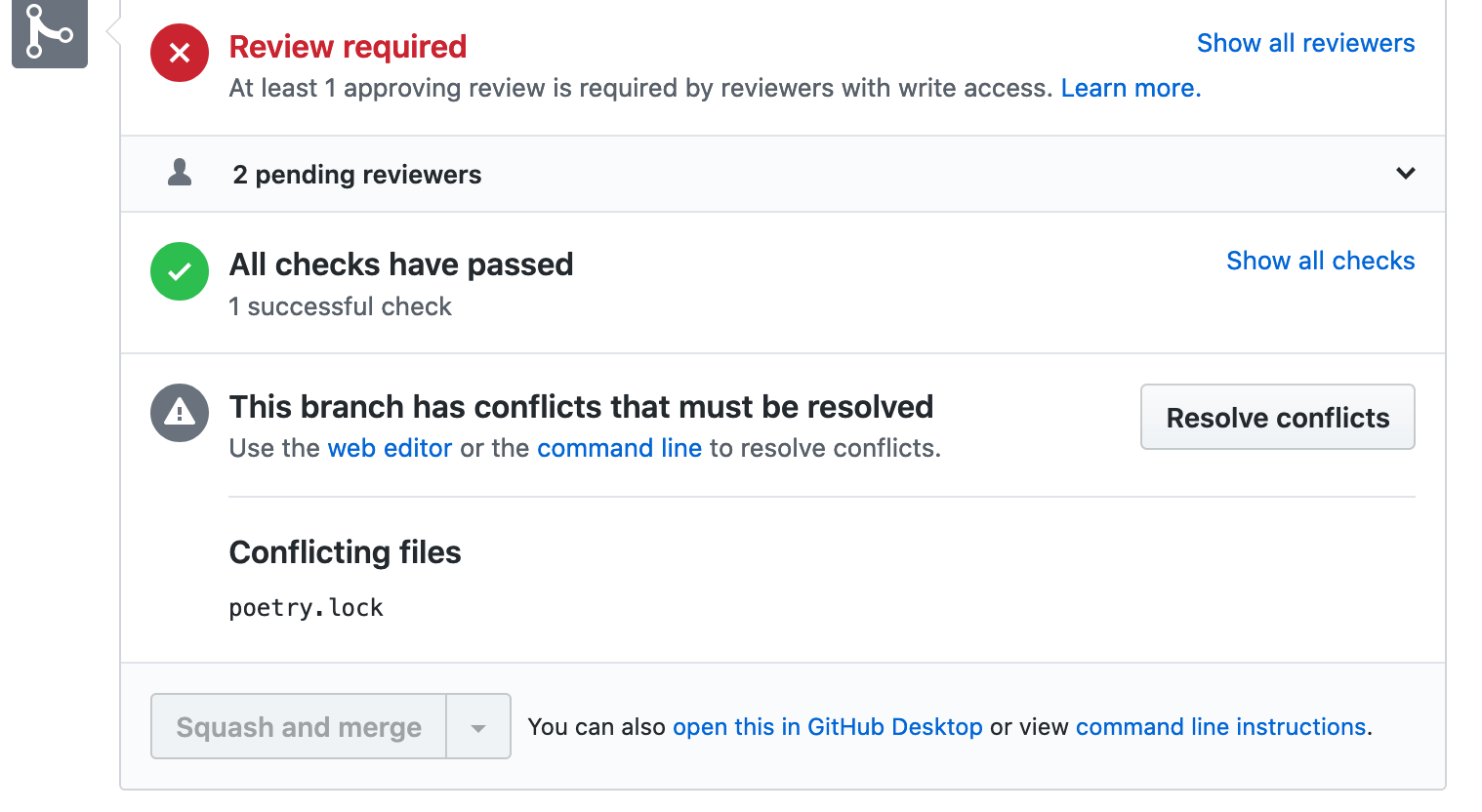
Suppose that you make a pull request to add a new dependency, but someone sneaks a new pull request in before you and have theirs landed in master before. Well, that's how you end up in this place:
So how do you resolve that?
So, you go back to your branch and run something like:
git checkout master
git pull origin master
git checkout my-branch
git merge master
Now you get this in git status:
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: poetry.lock
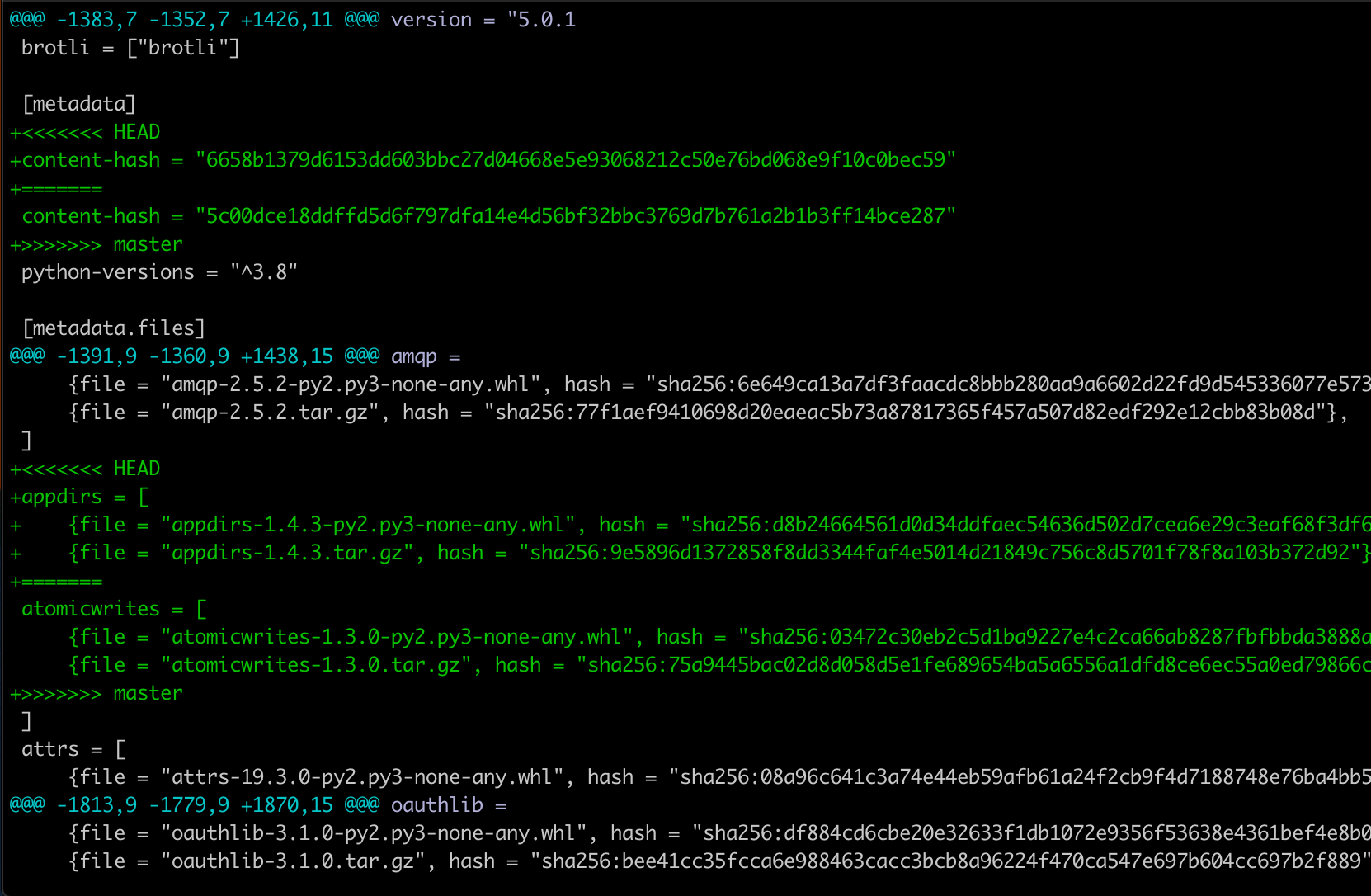
And the contents of poetry.lock looks something like this:
I wish there just was a way poetry itself could just figure fix this.
What you need to do is to run:
# Get poetry.lock to look like it does in master
git checkout --theirs poetry.lock
# Rewrite the lock file
poetry lock --no-update
Now, your poetry.lock file should correctly reflect the pyproject.toml that has been merged from master.
To finish up, resolve the conflict:
git add poetry.lock
git commit -a -m "conflict resolved"
# and most likely needed
poetry install
content-hash
Inside the poetry.lock file there's the lock file's hash. It looks like this:
[metadata]
content-hash = "875b6a3628489658b323851ce6fe8dafacd5f69e5150d8bb92b8c53da954c1be"
So, as can be seen in my screenshot, when git conflicted on this it looks like this:
[metadata]
+<<<<<<< HEAD
+content-hash = "6658b1379d6153dd603bbc27d04668e5e93068212c50e76bd068e9f10c0bec59"
+=======
content-hash = "5c00dce18ddffd5d6f797dfa14e4d56bf32bbc3769d7b761a2b1b3ff14bce287"
+>>>>>>> master
Basically, the content-hash = "5c00dce1... is what you'd find in master and content-hash = "6658b137... is what you would see in your branch before the conflict.
When you run that poetry lock you can validate that the new locking worked because it should be a hash. One that is neither 5c00dce1... or 6658b137....
Notes
I'm still new to poetry and I'm learning. This was just some loud note-to-self so I can remember for next time.
I don't yet know what else can be automated if there's a conflict in pyproject.toml too. And what do you do if there are serious underlying conflicts in Python packages, like they added a package that requires somelib<=0.99 and you added something that requires somelib>=1.11.
Also, perhaps there are ongoing efforts within the poetry project to help out with this.
UPDATE Feb 12, 2020
My colleague informed me that this change was actually NOT what I wanted. poetry lock actually updates some dependencies as it makes a completely new lock file. I didn't immediately notice that in my case because the lock file is large. See this open issue which is about the ability to update the lock file without upgrading any other dependencies.
UPDATE June 24, 2021
To re-lock the file, use poetry lock --no-update after you've run git checkout --theirs poetry.lock.