This is a quick-and-dirty how-to on how to use csso to handle the minification/compression of CSS in django-pipeline.
First create a file called compressors.py somewhere in your project. Make it something like this:
import subprocess
from pipeline.compressors import CompressorBase
from django.conf import settings
class CSSOCompressor(CompressorBase):
def compress_css(self, css):
proc = subprocess.Popen(
[
settings.PIPELINE['CSSO_BINARY'],
'--restructure-off'
],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
)
css_out = proc.communicate(
input=css.encode('utf-8')
)[0].decode('utf-8')
# was_size = len(css)
# new_size = len(css_out)
# print('FROM {} to {} Saved {} ({!r})'.format(
# was_size,
# new_size,
# was_size - new_size,
# css_out[:50]
# ))
return css_out
In your settings.py where you configure django-pipeline make it something like this:
PIPELINE = {
'STYLESHEETS': PIPELINE_CSS,
'JAVASCRIPT': PIPELINE_JS,
# These two important lines.
'CSSO_BINARY': path('node_modules/.bin/csso'),
# Adjust the dotted path name to where you put your compressors.py
'CSS_COMPRESSOR': 'peterbecom.compressors.CSSOCompressor',
'JS_COMPRESSOR': ...
Next, install csso-cli in your project root (where you have the package.json). It's a bit confusing. The main package is called csso but to have a command line app you need to install csso-cli and when that's been installed you'll have a command line app called csso.
$ yarn add csso-cli
or
$ npm i --save csso-cli
Check that it installed:
$ ./node_modules/.bin/csso --version 3.5.0
And that's it!
--restructure-off
So csso has an advanced feature to restructure the CSS and not just remove whitespace and not needed semicolons. It costs a bit of time to do that so if you want to squeeze the extra milliseconds out, enable it. Trading time for space.
See this benchmark for a comparison with and without --restructure-off in csso.
Why csso you might ask
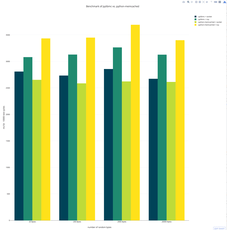
Check out the latest result from css-minification-benchmark. It's not super easy to read by it seems the best performing one in terms of space (bytes) is crass written by my friend and former colleague @mattbasta. However, by far the fastest is csso when using --restructre-off. Minifiying font-awesome.css with crass takes 326.52 ms versus 3.84 ms in csso.
But what's great about csso is Roman @lahmatiy Dvornov. I call him a friend too for all the help and work he's done on minimalcss (not a CSS minification tool by the way). Roman really understands CSS and csso is actively maintained by him and other smart people who actually get into the scary weeds of CSS browser hacks. That gives me more confidence to recommend csso. Also, squeezing a couple bytes extra out of your .min.css files isn't important when gzip comes into play. It's better that the minification tool is solid and stable.
Check out Roman's slides which, even if you don't read it all, goes to show that CSS minification is so much more than just regex replacing whitespace.
Also crass admits as one of its disadvantages: "Certain "CSS hacks" that use invalid syntax are unsupported".