I have a Zope web app that uses hand coded SQL (PostgreSQL) statements. Similar to the old PHP. My only excuse for not using an ORM was that this project started in 2005 and at the time SQLAlchemy seemed like a nerdy mess with more undocumented quirks than it was worth losing hair over.
Anyway, several statements use ILIKE to get around the problem of making things case insensitive. Something like the Django ORM uses UPPER to get around it. So I wonder how much the ILIKE statement slows down compared to UPPER and the indexed equal operator. Obviously, neither ILIKE or UPPER can use an index.
Long story short, here are the numbers for selecting on about 10,000 index records:
# ONE
EXPLAIN ANALYZE SELECT ... FROM ... WHERE name = 'Abbaye';
Average: 0.14 milliseconds
# TWO
EXPLAIN ANALYZE SELECT ... FROM ... WHERE UPPER(name::text) = UPPER('Abbaye');
Average: 18.89 milliseconds
# THREE
EXPLAIN ANALYZE SELECT ... FROM ... WHERE name ILIKE 'Abbaye';
Average: 24.63 milliseconds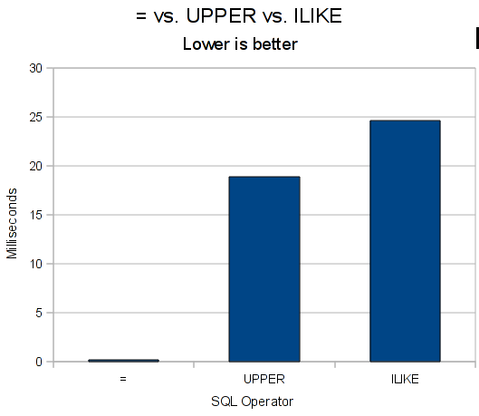
First of all, the conclusion is to use UPPER instead of ILIKE if you don't need to do regular expressions. Secondly, if at all possible try to use the equal operator first and foremost and only reside on the case insensitive one if you really need to.
Lastly, in PostgreSQL is there a quick and easy to use drop in alternative to make an equality operatorish thing for varchars that are case insensitive?
UPDATE 2014
There is an answer to the question just above: citext
Comments
FYI UPPER can use an index if you create the index to be uppercase, i.e.
CREATE INDEX foo on bar (upper(col));
after which a "select * from bar where upper(col) = "PETER"; should be alot faster.
Really?! I sort of not surprised. PostgreSQL rocks! I'll throw that in if and when I replace my ILIKE statements (that don't use wildcards) with UPPER ones.
Even ILIKE can use indexes, but only up to the first character where UPPER(x) != x and is not a wildcard, e.g. for numbers. The wildcard problem remains for plain LIKE as well. Examples:
(1) WHERE col ILIKE '123A'; -- will use index for the "123" prefix
(2) WHERE col ILIKE 'ABCD'; -- cannot use any b-tree index
(3) WHERE upper(col) LIKE upper('123A'); -- will use index on UPPER(col) for the entire value
(4) WHERE upper(col) LIKE upper('123%'); -- will use index for the "123" prefix
(5) WHERE upper(col) LIKE upper('%123'); -- cannot use any b-tree index
Cases 2 and 5 could work with some fulltext indexes, case 2 for sure, case 5 maybe (i seen this work in lucene)
Reverse indexes can be used along with upper for pattern matching at the end of strings.
An explanations is available here: http://technobytz.com/like-and-ilike-for-pattern-matching-in-postgresql.html