This is an update to a old blog post from 2006 called Fastest way to uniquify a list in Python. But this, time for Python 3.6. Why, because Python 3.6 preserves the order when inserting keys to a dictionary. How, because the way dicts are implemented in 3.6, the way it does that is different and as an implementation detail the order gets preserved. Then, in Python 3.7, which isn't released at the time of writing, that order preserving is guaranteed.
Anyway, Raymond Hettinger just shared a neat little way to uniqify a list. I thought I'd update my old post from 2006 to add list(dict.fromkeys('abracadabra')).
Functions
Reminder, there are two ways to uniqify a list. Order preserving and not order preserving. For example, the unique letters in peter is p, e, t, r in their "original order". As opposed to t, e, p, r.
def f1(seq): # Raymond Hettinger
hash_ = {}
[hash_.__setitem__(x, 1) for x in seq]
return hash_.keys()
def f3(seq):
# Not order preserving
keys = {}
for e in seq:
keys[e] = 1
return keys.keys()
def f5(seq, idfun=None): # Alex Martelli ******* order preserving
if idfun is None:
def idfun(x): return x
seen = {}
result = []
for item in seq:
marker = idfun(item)
# in old Python versions:
# if seen.has_key(marker)
# but in new ones:
if marker in seen:
continue
seen[marker] = 1
result.append(item)
return result
def f5b(seq, idfun=None): # Alex Martelli ******* order preserving
if idfun is None:
def idfun(x): return x
seen = {}
result = []
for item in seq:
marker = idfun(item)
# in old Python versions:
# if seen.has_key(marker)
# but in new ones:
if marker not in seen:
seen[marker] = 1
result.append(item)
return result
def f7(seq):
# Not order preserving
return list(set(seq))
def f8(seq): # Dave Kirby
# Order preserving
seen = set()
return [x for x in seq if x not in seen and not seen.add(x)]
def f9(seq):
# Not order preserving, even in Py >=3.6
return {}.fromkeys(seq).keys()
def f10(seq, idfun=None): # Andrew Dalke
# Order preserving
return list(_f10(seq, idfun))
def _f10(seq, idfun=None):
seen = set()
if idfun is None:
for x in seq:
if x in seen:
continue
seen.add(x)
yield x
else:
for x in seq:
x = idfun(x)
if x in seen:
continue
seen.add(x)
yield x
def f11(seq): # f10 but simpler
# Order preserving
return list(_f10(seq))
def f12(seq):
# Raymond Hettinger
# https://twitter.com/raymondh/status/944125570534621185
return list(dict.fromkeys(seq))
Results
FUNCTION ORDER PRESERVING MEAN MEDIAN f12 yes 111.0 112.2 f8 yes 266.3 266.4 f10 yes 304.0 299.1 f11 yes 314.3 312.9 f5 yes 486.8 479.7 f5b yes 494.7 498.0 f7 no 95.8 95.1 f9 no 100.8 100.9 f3 no 143.7 142.2 f1 no 406.4 408.4
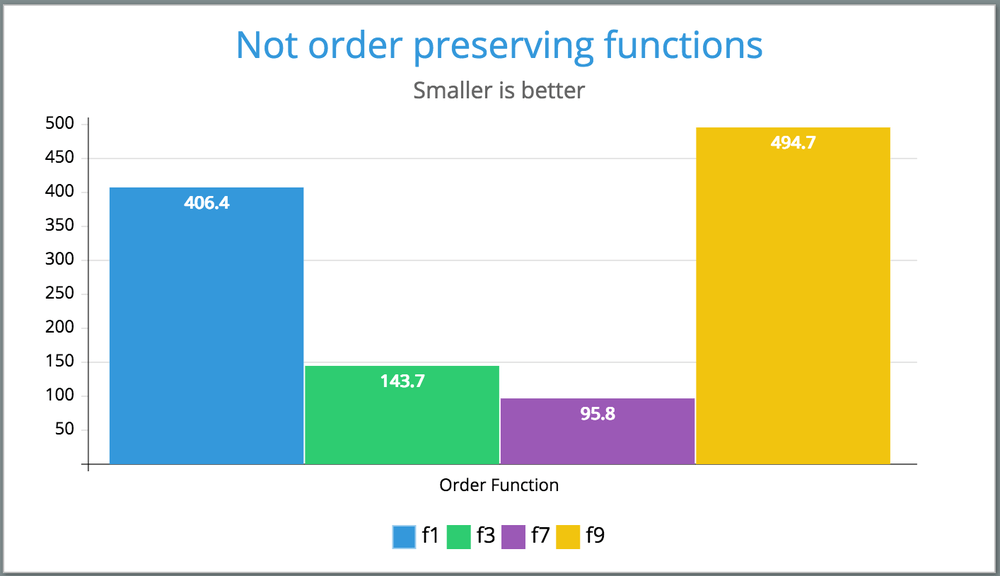
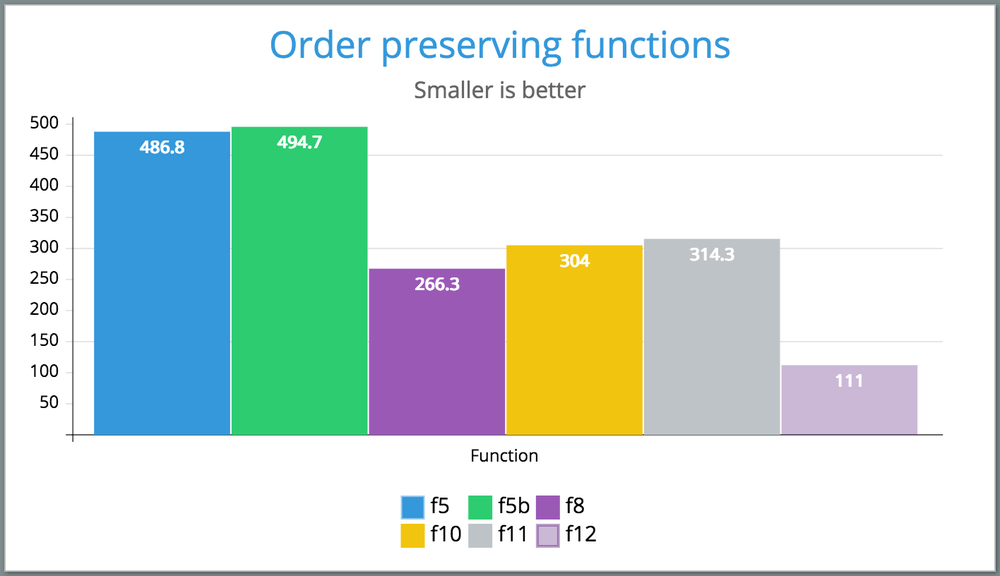
Conclusion
The fastest way to uniqify a list of hashable objects (basically immutable things) is:
list(set(seq))
And the fastest way, if the order is important is:
list(dict.fromkeys(seq))
Now we know.
Comments
Post your own commentWhat is this mysterious sequence "seq" that you're testing with? Can you please show the *whole* benchmark code?
See the link in the top to that gist.github.com
Thanks, missed that since it's "above the article". Other things:
- You say in Python 3.7 "order preserving is guaranteed" but following that link I only see Raymond saying "a guarantee for 3.7 is almost inevitable". Am I missing something again or are you overstating that?
- Better remove f2 from the list of functions to test, as it's suuuper slow.
- Would be good to include *min* as well, in addition to mean and median. As Veedrac argued at https://stackoverflow.com/a/24105845/1672429 - "all error in timing is positive [so] the shortest time has the least error in it". And *Raymond* uses min there as well (in his answer, the accepted one).
- I came up with four order-preserving solutions slower than Raymond's but much faster than the others. Then I also found them in the comments of the old blog post, ha. Here they are:
def f13(seq):
seen = set()
add = seen.add
return [add(x) or x for x in seq if x not in seen]
return [add(x) or x for x in seq if not x in seen]
return [x for x in seq if not (x in seen or add(x))]
return [x for x in seq if x not in seen and not add(x)]
- f1, f3 and f9 aren't quite right. They don't return a list but a "dict_keys" view object, which isn't fair, as that takes only O(1) time.
- What makes you think f9 doesn't preserve order? I don't see why it wouldn't, and it did preserve order in some tests I just did, including your script (after fixing the "dict_keys" issue by wrapping "list(...)" around it).
- In the comments under Raymond's answer https://stackoverflow.com/a/8220943/1672429 he also very strongly suggested using *min*: "Use the min() rather than the average of the timings. That is a recommendation from me, from Tim Peters, and from Guido van Rossum. The fastest time represents the best an algorithm can perform when the caches are loaded and the system isn't busy with other tasks. All the timings are noisy -- the fastest time is the least noisy. It is easy to show that the fastest timings are the most reproducible and therefore the most useful when timing two different implementations."
Nice analysis. f7 is now order preserving because it's backed by dictionaries, which are now going to be order preserving.
Sorry, make that will be... when 3.7 comes out. :)
Since Python 3.7, insertion-order dict’s are part of the language, as per the “official verdict” by BDFL: https://mail.python.org/pipermail/python-dev/2017-December/151283.html.