tl;dr; The previous (React) total JavaScript bundle size was: 36.2K Brotli compressed. The new (Preact) JavaScript bundle size was: 5.9K. I.e. 6 times smaller. Also, it appears to load faster in WebPageTest.
I have this page that is a Django server-side rendered page that has on it a form that looks something like this:
<div id="root">
<form action="https://songsear.ch/q/">
<input type="search" name="term" placeholder="Type your search here..." />
<button>Search</button>
</form>
</div>
It's a simple search form. But, to make it a bit better for users, I wrote a React widget that renders, into this document.querySelector('#root'), a near-identical <form> but with autocomplete functionality that displays suggestions as you type.
Anyway, I built that React bundle using create-react-app. I use the yarn run build command that generates...
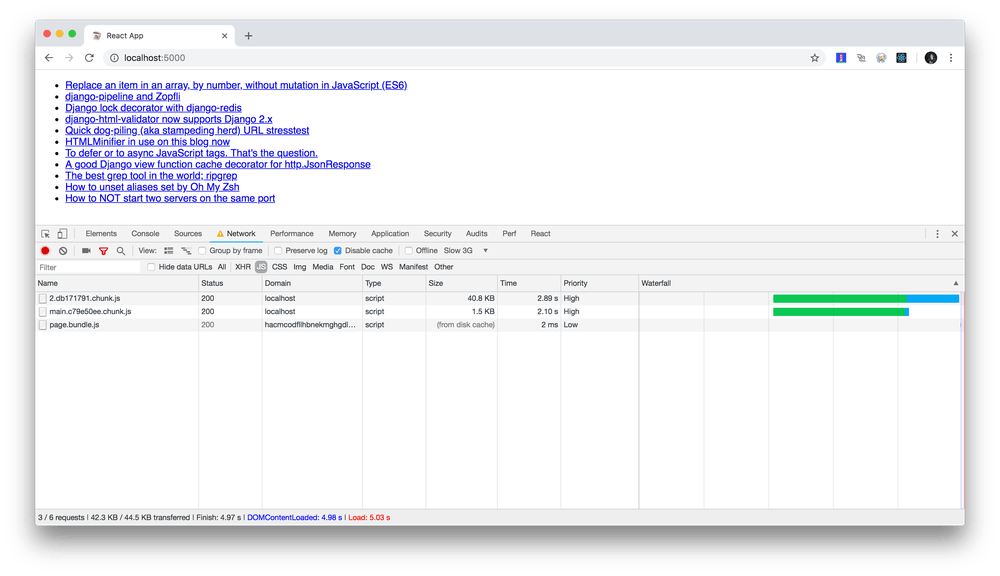
css/main.83463791.chunk.css- 1.4Kjs/main.ec6364ab.chunk.js- 9.0K (gzip 2.8K, br 2.5K)js/runtime~main.a8a9905a.js- 1.5K (gzip 754B, br 688B)js/2.b944397d.chunk.js- 119K (gzip 36K, br 33K)
Then, in Python, a piece of post-processing code copies the files from the build/static/ directory and inserts it into the rendered HTML file. The CSS gets injected as an inline <style> tag.
It's a simple little widget. No need for any service-workers or react-router or any global state stuff. (Actually, it only has 1 single runtime dependency outside the framework) I thought, how about moving this to Preact?
In comes preact-cli
The app used a couple of React hooks but they were easy to transform into class components. Now I just needed to run:
npx preact create --yarn widget name-of-my-preact-project
cd name-of-my-preact-project
mkdir src
cp ../name-of-React-project/src/App.js src/
code src/App.js
Then, I slowly moved over the src/App.js from the create-react-app project and slowly by slowly I did the various little things that you need to do. For example, to learn to build with preact build --no-prerender --no-service-worker and how I can override the default template.
Long story short, the new built bundles look like this:
style.82edf.css- 1.4Kbundle.d91f9.js- 18K (gzip 6.4K, br 5.9K)polyfills.9168d.js- 4.5K (gzip 1.8K, br 1.6K)
(The polyfills.9168d.js gets injected as a script tag if window.fetch is falsy)
Unfortunately, when I did the move from React to Preact I did make some small fixes. Doing the "migration" I noticed a block of code that was never used so that gives the build bundle from Preact a slight advantage. But I think it's nominal.
In conclusion: The previous total JavaScript bundle size was: 36.2K (Brotli compressed). The new JavaScript bundle size was: 5.9K (Brotli compressed). I.e. 6 times smaller. But if you worry about the total amount of JavaScript to parse and execute, the size difference uncompressed was 129K vs. 18K. I.e. 7 times smaller. I can only speculate but I do suspect you need less CPU/battery to process 18K instead of 129K if CPU/batter matters more (or closer to) than network I/O.

Rendering speed difference
Rendering speed is so darn hard to measure on the web because the app is so small. Plus, there's so much else going on that matters.
However, using WebPageTest I can do a visual comparison with the "Mobile - Slow 3G" preset. It'll be a somewhat decent measurement of the total time of downloading, parsing and executing. Thing is, the server-side rended HTML form has a button. But the React/Preact widget that takes over the DOM hides that submit button. So, using the screenshots that WebPageTest provides, I can deduce that the Preact widget completes 0.8 seconds faster than the React widget. (I.e. instead of 4.4s it became 3.9s)
Truth be told, I'm not sure how predictable or reproducible is. I ran that WebPageTest visual comparison more than once and the results can vary significantly. I'm not even sure which run I'm referring to here (in the screenshot) but the React widget version was never faster.
Conclusion and thoughts
Unsurprisingly, Preact is smaller because you simply get less from that framework. E.g. synthetic events. I was lucky. My app uses onChange which I could easily "migrate" to onInput and I managed to get it to work pretty easily. I'm glad the widget app was so small and that I don't depend on any React specific third-party dependencies.
But! In WebPageTest Visual Comparison it was on "Mobile - Slow 3G" which only represents a small portion of the traffic. Mobile is a huge portion of the traffic but "Slow 3G" is not. When you do a Desktop comparison the difference is roughtly 0.1s.
Also, in total, that page is made up of 3 major elements
- The server-side rendered HTML
- The progressive JavaScript widget (what this blog post is about)
- A piece of JavaScript initiated banner ad
That HTML controls the "First Meaningful Paint" which takes 3 seconds. And the whole shebang, including the banner ad, takes a total of about 9s. So, all this work of rewriting a React app to Preact saved me 0.8s out of the total of 9s.
Web performance is hard and complicated. Every little counts, but keep your eye on the big ticket items assuming there's something you can do about them.
At the time of writing, preact-cli uses Preact 8.2 and I'm eager to see how Preact X feels. Apparently, since April 2019, it's in beta. Looking forward to giving it a try!