The documentation about how to use synonyms in Elasticsearch is good but because it's such an advanced topic, even if you read the documentation carefully, you're still left with lots of questions. Let me show you some things I've learned about how to use synonyms in Python with elasticsearch-dsl.
What's the nature of your documents?
I'm originally from Sweden but moved to London, UK in 1999 and started blogging a few years after. So I wrote most of my English with British English spelling. E.g. "centre" instead of "center". Later I moved to California in the US and slowly started to change my own English over to American English. I kept blogging but now I would prefer to write "center" instead of "centre".
Another example... Certain technical words or namings are tricky. For example, is it "go" or is it "golang"? Is it "React" or is it "ReactJS"? Is it "PostgreSQL" or "Postgres". I never know. Not only is it sometimes hard to know which is right because people use them differently, but also sometimes "brands" like that change over time since inception, the creator might have preferred something but the masses of people call it something else.
So with all that in mind, not only has the nature of my documents (my blog post texts) changed in terminology over the years. My visitors are also coming both from British English and American English. Or, suppose that I knew the perfect way to phrase that relational database that starts with "Postg...". Even if my text is always spelled one particular way, perfectly, my visitors will most likely refer to it as "postgres" sometimes and "postgresql" sometimes.
The simple solution, match all!
Create a custom analyzer
Let's jump straight into the code. People who have used elasticsearch_dsl should be familiar with most of this:
from elasticsearch_dsl import (
DocType,
Text,
Index,
analyzer,
Keyword,
token_filter,
)
from django.conf import settings
index = Index(settings.ES_INDEX)
index.settings(**settings.ES_INDEX_SETTINGS)
synonym_tokenfilter = token_filter(
'synonym_tokenfilter',
'synonym',
synonyms=[
'reactjs, react',
],
)
text_analyzer = analyzer(
'text_analyzer',
tokenizer='standard',
filter=[
'standard',
'lowercase',
'stop',
synonym_tokenfilter,
'snowball',
],
char_filter=['html_strip']
)
class BlogItemDoc(DocType):
oid = Keyword(required=True)
title = Text(
required=True,
analyzer=text_analyzer
)
text = Text(analyzer=text_analyzer)
index.doc_type(BlogItemDoc)
This code above is copied from the "real code" but a lot of distracting things that aren't important to the point, have been removed.
The magic sauce here is that you create a token_filter and you can call it whatever you want. I called mine synonym_tokenfilter and that's also what the instance variable is called.
Notice the list of synonyms. It's a plain list of strings. Specifically, it's a list of 1 string reactjs, react.
Let's see how Elasticsearch analyzes this:
First with the text react.
$ curl -XGET 'http://127.0.0.1:9200/peterbecom/_analyze?analyzer=text_analyzer&text=react&pretty=1'
{
"tokens" : [
{
"token" : "react",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "reactj",
"start_offset" : 0,
"end_offset" : 5,
"type" : "SYNONYM",
"position" : 0
}
]
}
Note that the analyzer snowball, converted reactjs to reactj which is wrong in a sense, because there's not plural "reacts", but it ultimately doesn't matter much. At least not in this particular case.
Secondly, analyze it with the text reactjs:
$ curl -XGET 'http://127.0.0.1:9200/peterbecom/_analyze?analyzer=text_analyzer&text=reactjs&pretty=1'
{
"tokens" : [
{
"token" : "reactj",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "react",
"start_offset" : 0,
"end_offset" : 7,
"type" : "SYNONYM",
"position" : 0
}
]
}
Same tokens! Just different order.
Test it for reals
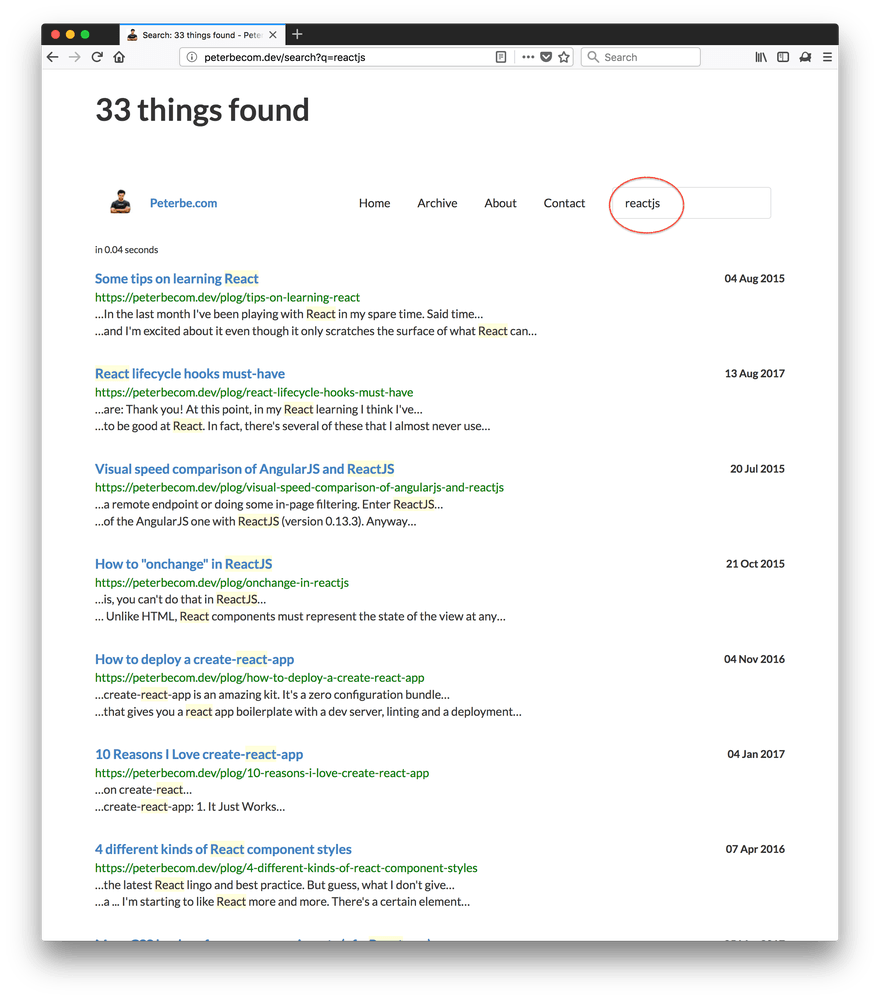
Now, the real proof is in actually doing a search on this. Look at these two screenshots:
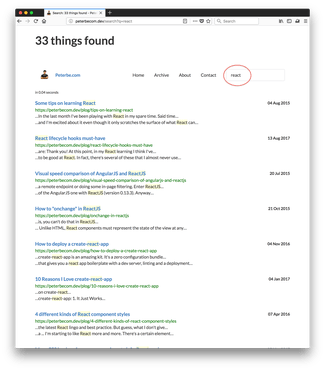
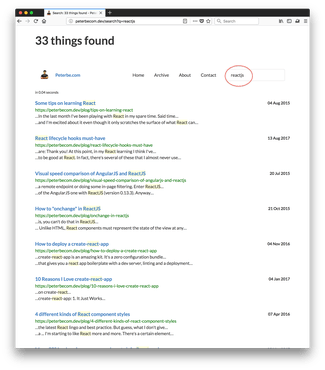
It worked! Different ways of phrasing your search but ultimately found all the documents that matched independent of different people or different authors might prefer to spell it.
Try it for yourself:
What it looked like before
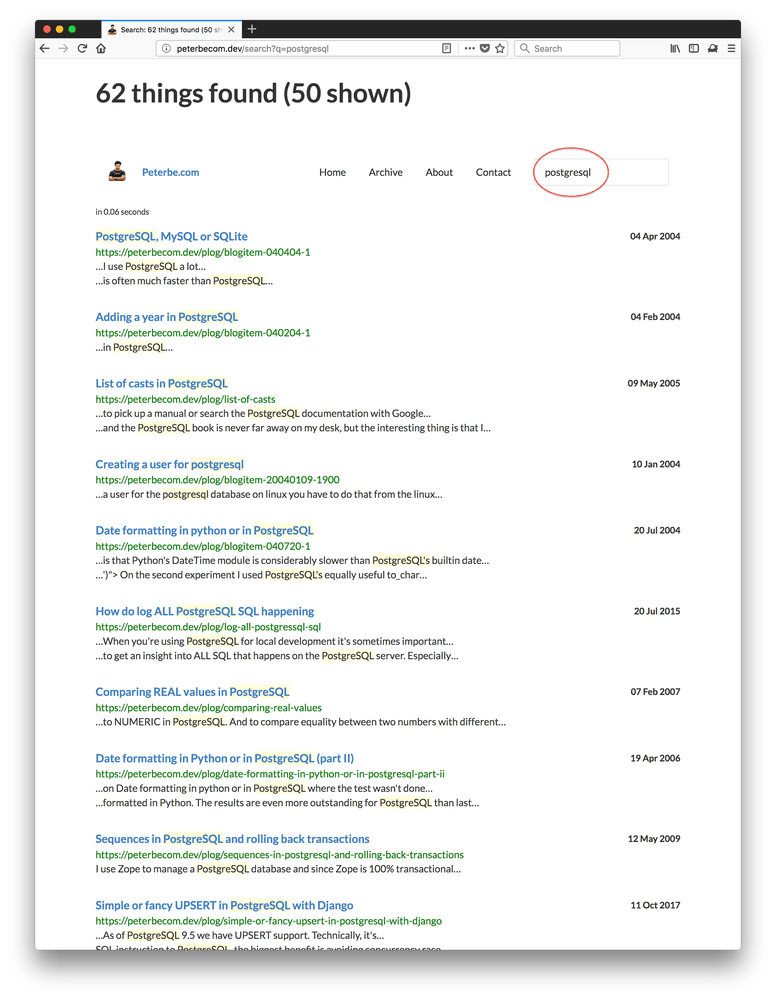
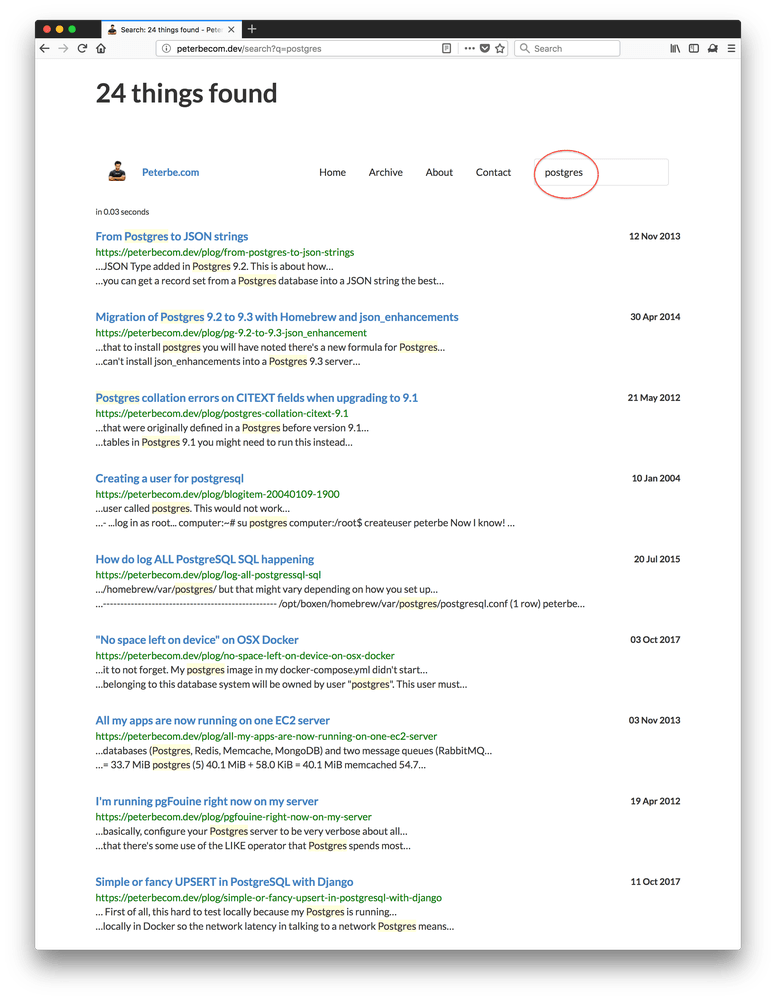
Check out these two screenshots of how it would look like before, when synonyms for postgres and postgresql had not been set up yet:
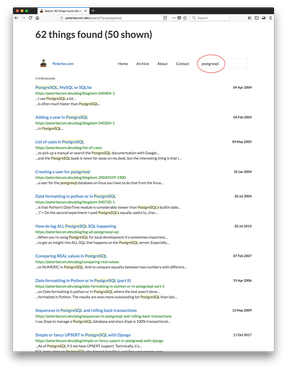
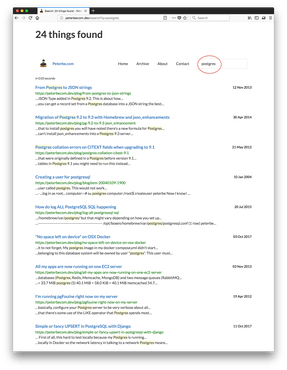
One immediate thought I have is what a mess I've been in blogging about that database. Clearly I struggled to pick one way to spell it consistently.
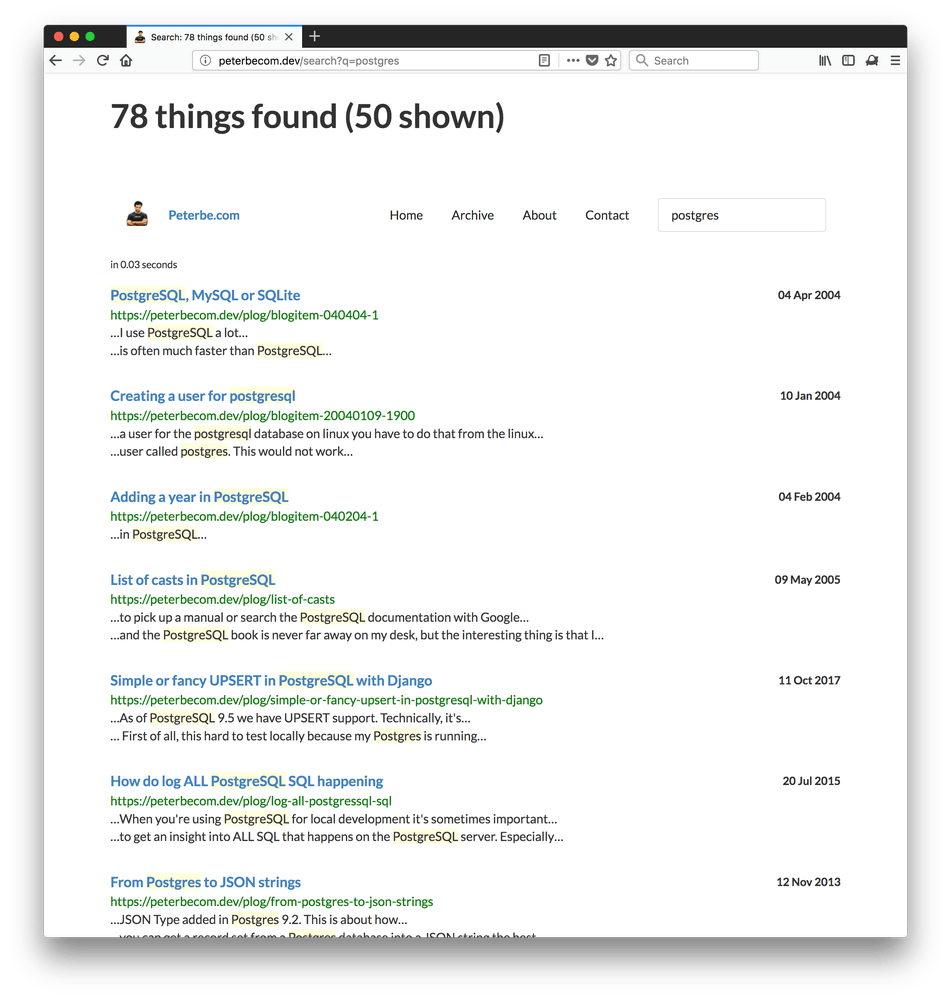
And here's what it would look like once that synonym has been set up:
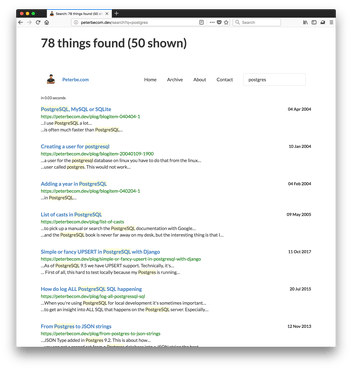
"go" versus "golang"
Go is a programming language. That term, too, struggles with a name ambiguity. Granted, I rarely hear people say "golang", but it's definitely a written word that turns up a lot.
The problem with setting up a synonym for go == golang is that "go" is common English word. It's also the stem of the word "going" and such. So if you set up a synonym, like I did for react and reactjs above, this is what happens:
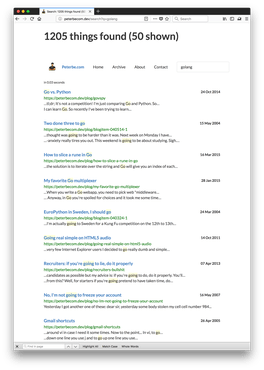
This is now the exact search results as if I had searched for go. But look what it matched! It matched "Go" (good) but also "Going real simple..." (bad) and "...I should go" (bad).
If someone searches for the simple term "go" they probably intend to search for the Go programming language. All that snowball stemming is critical for a bunch of other non-computer-term searches so we can't remove the stemming.
The solution is to use what's called "Simple Contraction". And it looks like this:
all_synonyms = [
'go => golang',
'react => reactjs',
'postgres => postgresql',
]
That basically means that a search for go is a search for golang. And a document that uses the word go (alone) is indexed as golang.
What happens is that the word go gets converted to golang which doesn't get stemming converted down to any other forms.
However, this is no silver bullet. Any search for the term go is ultimately a search for the word golang and the regular English word go. So the benefit of all of this was that we got rid of search results matching on going and gone.
What you have to decide...
The case for go is similar to the case for react. Both of these words are nouns but they're also verbs.
Should people find "reacting to events" when they search for "react"?
If so, use react, reactjs in the synonyms list.
Should people only find documents related to noun "React" when they search for "event handing in react"?
If so, use react => reactjs in the synonyms list.
It's up to you and your documents and what your users tend to search for.
Bonus! For American vs British English
AVKO.org publishes a list of all British to American English synonyms. You can download the whole list here. Unfortunately I can't find a license for this file but the compiled synonyms file is part of this repo which is licensed under MIT.
I download this list and keep it in the repo. Then when setting up the analyzer and token filters I load it in like this:
synonyms_root = os.path.join(
settings.BASE_DIR, 'peterbecom/es-synonyms'
)
american_british_syns_fn = os.path.join(
synonyms_root, 'be-ae.synonyms'
)
with open(american_british_syns_fn) as f:
for line in f:
if (
'=>' not in line or
line.strip().startswith('#')
):
continue
all_synonyms.append(line.strip())
Now I can finally enjoy not having to worry about the fact that sometimes I spell it "license" and sometimes I spell it "licence". It's all the same now. Brits and Americans, rejoice on common ground!
Bonus! For terrible spellers
Although I don't have a big problem with this on my techy blog but you can use the Simple Contraction technique to list unambiguously bad spelling. Add dont => don't to the list of synonyms and a search for dont is a search for don't.
Last but not least, the official Elasticsearch documentation is the place to go. This blog post hopefully phrases it in more approachable terms. Especially for Python peeps.