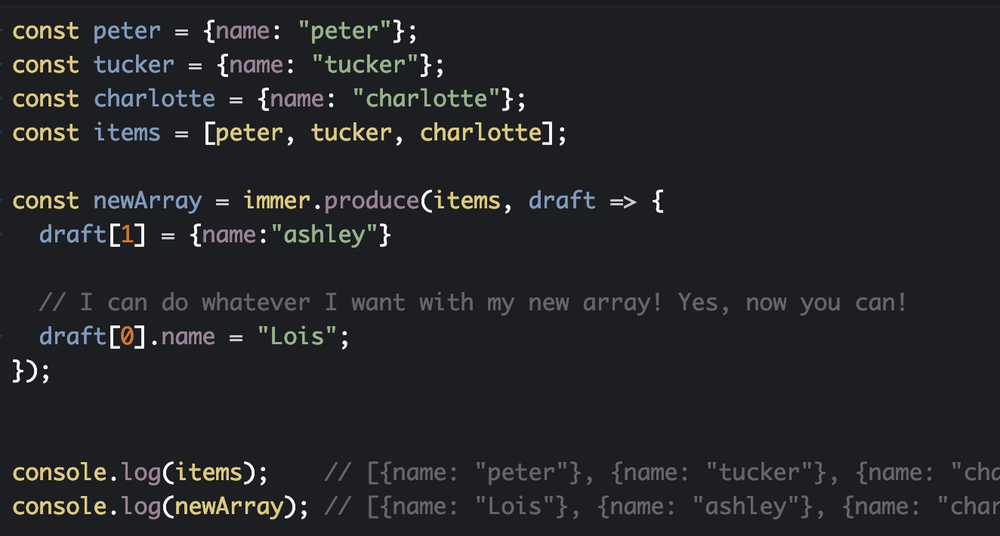
React Hooks isn't here yet but when it comes I'll be all over that, replacing many of my classes with functions.
However, as of React 16.6 there's this awesome new React.memo() thing which is such a neat solution. Why didn't I think of that, myself, sooner?!
Anyway, one of the subtle benefits of it is that writing functions minify a lot better than classes when Babel'ifying your ES6 code.
To test that, I took one of my project's classes, which needed to be "PureComponent":
class ShowAutocompleteSuggestionSong extends React.PureComponent {
render() {
const { song } = this.props;
return (
<div className="media autocomplete-suggestion-song">
<div className="media-left">
<img
className={
song.image && song.image.preview
? 'img-rounded lazyload preview'
: 'img-rounded lazyload'
}
src={
song.image && song.image.preview
? song.image.preview
: placeholderImage
}
data-src={
song.image ? absolutifyUrl(song.image.url) : placeholderImage
}
alt={song.name}
/>
</div>
<div className="media-body">
<h5 className="artist-name">
<b>{song.name}</b>
{' by '}
<span>{song.artist.name}</span>
</h5>
{song.fragments.map((fragment, i) => {
return <p key={i} dangerouslySetInnerHTML={{ __html: fragment }} />;
})}
</div>
</div>
);
}
}
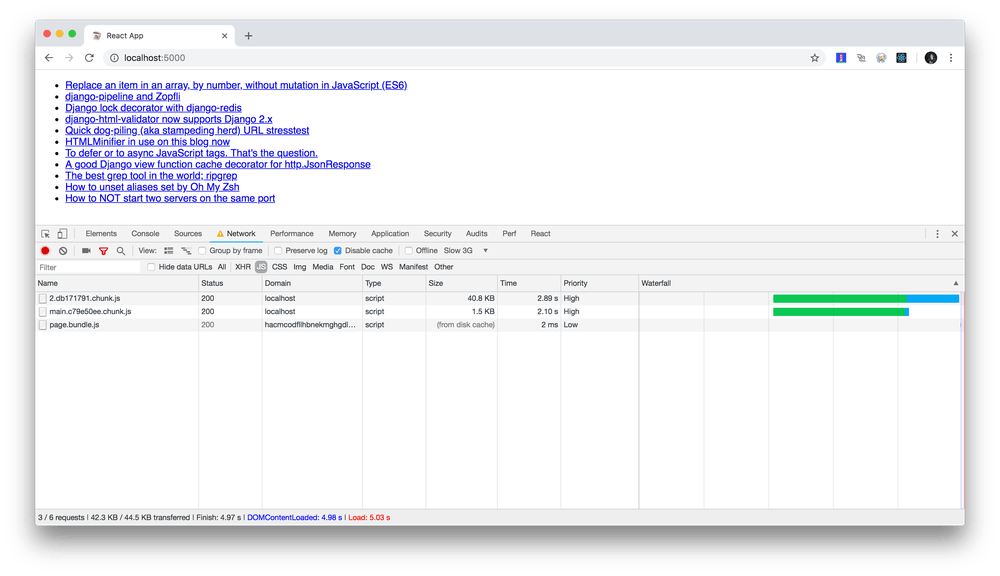
Minified it weights 1,893 bytes and looks like this:

Minified PureComponent class
When re-written with React.memo it looks like this:
const ShowAutocompleteSuggestionSong = React.memo(({ song }) => {
return (
<div className="media autocomplete-suggestion-song">
<div className="media-left">
<img
className={
song.image && song.image.preview
? 'img-rounded lazyload preview'
: 'img-rounded lazyload'
}
src={
song.image && song.image.preview
? song.image.preview
: placeholderImage
}
data-src={
song.image ? absolutifyUrl(song.image.url) : placeholderImage
}
alt={song.name}
/>
</div>
<div className="media-body">
<h5 className="artist-name">
<b>{song.name}</b>
{' by '}
<span>{song.artist.name}</span>
</h5>
{song.fragments.map((fragment, i) => {
return <p key={i} dangerouslySetInnerHTML={{ __html: fragment }} />;
})}
</div>
</div>
);
});
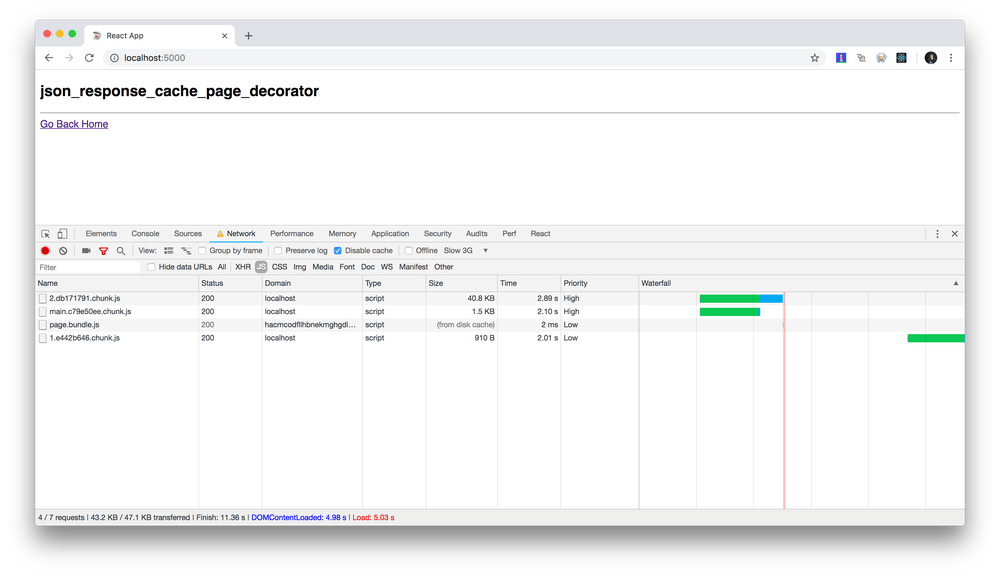
Minified it weights 783 bytes and looks like this:

Minified React.memo function
Highly scientific measurement. Yeah, I know. (Joking)
Perhaps it's stating the obvious but part of the ES5 code that it generates, from classes can be reused for other classes.
Anyway, it's neat and worth considering to squeeze some bytes out. And the bonus is that it gets you prepared for Hooks in React 16.7.