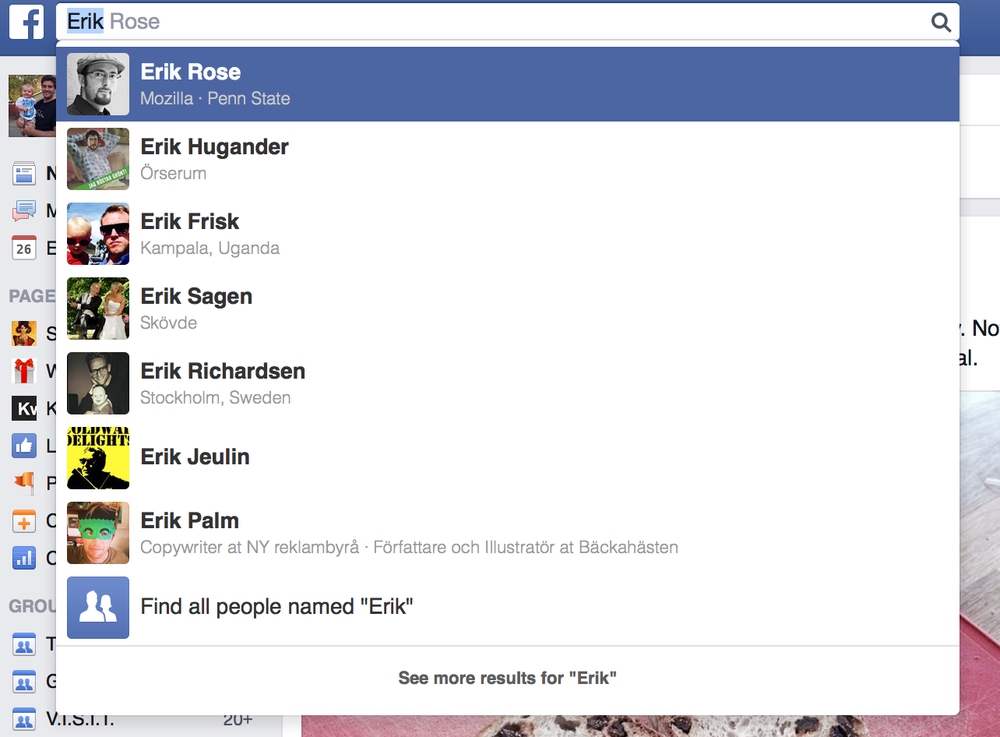
Sometimes it feels like there's almost no unique names amongst my Facebook friends. Whenever I use the search function and start typing someones name at least two friends' names pop up.
However, I only have one friend called Åsa and one friend called Conrad. So it got me wondering how many of my friends names are unique?
So I pulled down the names of all my 500+ friends and counted them. The results were suprising!
| 0 in common | 291 |
| 1 in common | 53 |
| 2 in common | 15 |
| 3 in common | 10 |
| 4 in common | 1 |
| 5 in common | 3 |
| 6 in common | 2 |
That means that 56% of my friends' names are unique! Much more than I expected. I should add, the bulk of my friends are primarily from two countries: USA and Sweden. From all over the world too but these are the most common. However, because of this I have some friends who have the locale's spelling. I.e. "Michael" in USA versus "Mikael" in Sweden.
So, if I manually go through the list and look at some names and come up with some aliases so that Eric and Erik counts as the same name, I get a lot less uniqueness. The list I made is available here and it's very much a quick judgement call based on a rough idea of the "stemming" of these names.
It actually didn't help that much. The spread now looks like this:
| 0 in common | 260 |
| 1 in common | 44 |
| 2 in common | 14 |
| 3 in common | 12 |
| 4 in common | 6 |
| 5 in common | 2 |
| 6 in common | 1 |
| 7 in common | 4 |
And the number of people with unique names goes down to 50.1%. Still more than half.
Last but not least, the most common names for me were:
- Michael (8 people)
- Mat (8)
- Eric (8)
- Christopher (8)
- Dave (7)
- Sara (6)

 All of this week and last week I'm working at a client's office in west London. So I've been away from the sanctuary of our office now for a while. At my usual office I have bought some nice Twinings Earl Grey tea bags. Definitely a favorite of mine.
All of this week and last week I'm working at a client's office in west London. So I've been away from the sanctuary of our office now for a while. At my usual office I have bought some nice Twinings Earl Grey tea bags. Definitely a favorite of mine.