A project I started before Christmas (i.e. about a month ago) is now production ready.
mincss (code on github) is a tool that when given a URL (or multiple URLs) downloads that page and all its CSS and compares each and every selector in the CSS and finds out which ones aren't used. The outcome is a copy of the original CSS but with the selectors not found in the document(s) removed. It goes something like this:
>>> from mincss.processor import Processor
>>> p = Processor()
>>> p.process_url('https://www.peterbe.com')
>>> p.process()
>>> p.inlines
[]
>>> p.links
[<mincss.processor.LinkResult object at 0x10a3bbe50>, <mincss.processor.LinkResult object at 0x10a4d4e90>]
>>> one = p.links[0]
>>> one.href
'//d1ac1bzf3lrf3c.cloudfront.net/static/CACHE/css/c98c3dfc8525.css'
>>> len(one.before)
83108
>>> len(one.after)
10062
>>> one.after[:70]
u'header {display:block}html{font-size:100%;-webkit-text-size-adjust:100'
To whet your appetite, running it on any one of my pages here on my blog it goes from: 82Kb down to 7Kb. Before you say anything; yes I know its because I using a massive (uncustomized) Twitter Bootstrap file that contains all sorts of useful CSS that I'm not using more than 10% of. And yes, those 10% on one page might be different from the 10% on another page and between them it's something like 15%. Add a third page and it's 20% etc. But, because I'm just doing one page at a time, I can be certain it will be enough.
One way of using mincss is to run it on the command line and look at the ouput, then audit it and give yourself an idea of selectors that aren't used. A safer way is to just do one page at a time. It's safer.
The way it works is that it parses the CSS payload (from inline blocks or link tags) with a relatively advanced regular expression and then loops over each selector one at a time and runs it with cssselect (which uses lxml) to see if the selector is used anywhere. If the selector isn't used the selector is removed.
I know I'm not explaining it well so I put together a little example implementation which you can download and run locally just to see how it works.
Now, regarding Javascript and DOM manipulations and stuff; there's not a lot you can do about that. If you know exactly what your Javascript does, for example, creating a div with class loggedin-footer you can prepare your CSS to tell mincss to leave it alone by adding /* no mincss */ somewhere in the block. Again, look at the example implementation for how this can work.
An alternative is to instead of using urllib.urlopen() you could use a headless browser like PhantomJS which will run it with some Javascript rendering but you'll never cover all bases. For example, your page might have something like this:
$(function() {
$.getJSON('/is-logged-in', function(res) {
if (res.logged_in) {
$('<div class="loggedin-footer">').appendTo($('#footer'));
}
});
});
But let's not focus on what it can not do.
I think this can be a great tool for all of us who either just download a bloated CSS framework or you have a legacy CSS that hasn't been updated as new HTML is added and removed.
The code is Open Source (of course) and patiently awaiting your pull requests. There's almost full test coverage and there's still work to be done to improve the code such as finding more bugs and optimizing.
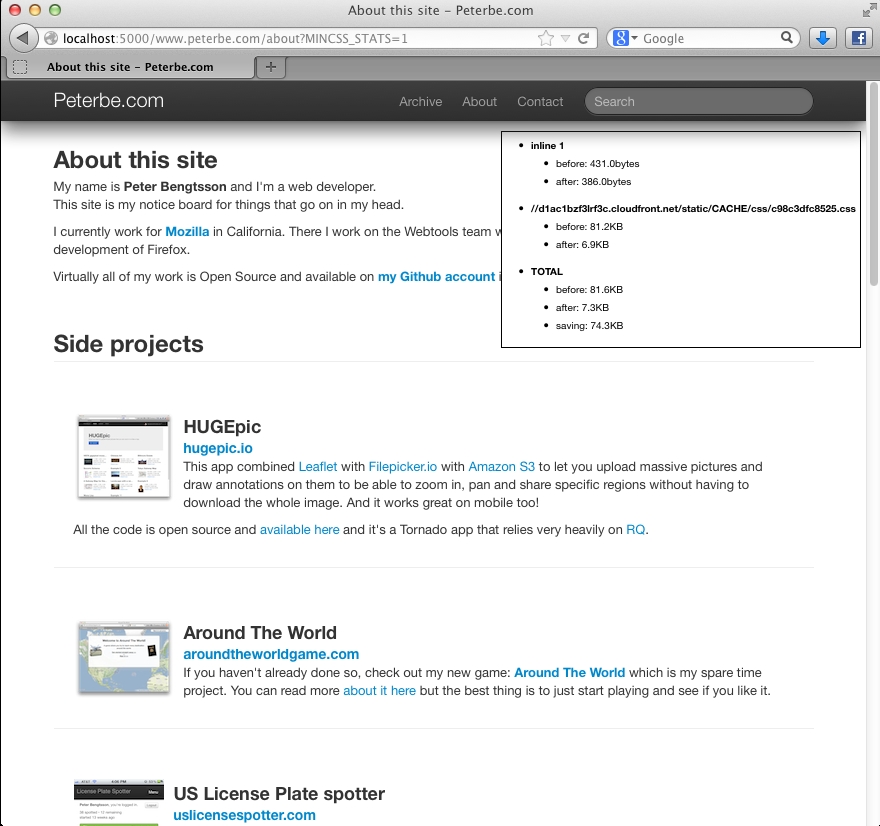
Also, there's a rough proxy server you can start that attempts to run it on any URL. You start it like this:
pip install Flask cd mincss/proxy python app.py
and then you just visit something like http://localhost:5000/www.peterbe.com/about and you can see it in action. That script needs some love since it's using lxml to render the processed output which does weird things to some DOM elements.
I hope it's of use to you.
UPDATE
Published a blog post about using mincss in action
UPDATE 2
cssmin now supports downloading using PhantomJS which means that Javascript rendering will work. See this announcement
UPDATE 3
Version 0.8 is 500% faster now for large documents. Make sure you upgrade!