Performance of truth checking a JavaScript object
February 3, 2020
0 comments Node, JavaScript
I'm working on a Node project that involves large transformations of large sets of data here and there. For example:
if (!Object.keys(this.allTitles).length) {
...
In my case, that this.allTitles is a plain object with about 30,000 key/value pairs. That particular line of code actually only runs 1 single time so if it's hundreds of milliseconds, it's really doesn't matter that much. However, that's not a guarantee! What if you had something like this:
for (const thing of things) {
if (!Object.keys(someObj).length) {
// mutate someObj
}
}
then, you'd potentially have a performance degradation once someObj becomes considerably large. And it gets particularly degraded if the length of things is considerably large as it would do the operation many times.
Actually, consider this:
const obj = {};
[...Array(30000)].forEach((_, i) => {
obj[i] = i;
});
console.time("Truthcheck obj");
[...Array(100)].forEach((_, i) => {
return !!Object.keys(obj).length;
});
console.timeEnd("Truthcheck obj");
On my macBook with Node 13.5, this outputs:
Truthcheck obj: 260.564ms
Maps
The MDN page on Map has a nice comparison, in terms of performance, between Map and regular object. Consider this super simple benchmark:
const obj = {};
const map = new Map();
[...Array(30000)].forEach((_, i) => {
obj[i] = i;
map.set(i, i);
});
console.time("Truthcheck obj");
[...Array(100)].forEach((_, i) => {
return !!Object.keys(obj).length;
});
console.timeEnd("Truthcheck obj");
console.time("Truthcheck map");
[...Array(100)].forEach((_, i) => {
return !!map.size;
});
console.timeEnd("Truthcheck map");
So, fill a Map instance and a plain object with 30,000 keys and values. Then, for each in turn, check if the thing is truthy 100 times. The output I get:
Truthcheck obj: 235.017ms Truthcheck map: 0.029ms
That's not unexpected. The map instance maintains a size counter, which increments on .set (if the key is new), so doing that "truthy" check just takes O(1) seconds.
Conclusion
Don't run to rewrite everything to Maps!
In fact, I took the above mentioned little benchmark and changed the times to be a 3,000 item map and obj (instead of 30,000) and only did 10 iterations (instead of 100) and then the numbers are:
Truthcheck obj: 0.991ms Truthcheck map: 0.044ms
These kinds of small numbers are very unlikely to matter in the scope of other things going on.
Anyway, consider using Map if you fear that you might be working with really reeeeally large mappings.
How to split a block of HTML with Cheerio in NodeJS
January 3, 2020
2 comments Node, JavaScript
cheerio is a great Node library for processing HTML. It's faster than JSDOM and years and years of jQuery usage makes the API feel yummily familiar.
What if you have a piece of HTML that you want to split up into multiple blocks? For example, you have this:
<div>Prelude</div>
<h2>First Header</h2>
<p>Paragraph <b>here</b>.</p>
<p>Another paragraph.</p>
<h2 id="second">Second Header</h2>
<ul>
<li>One</li>
<li>Two</li>
</ul>
<blockquote>End quote!</blockquote>
and you want to get this split by the <h2> tags so you end up with 3 (in this example) distinct blocks of HTML, like this:
first one
<div>Prelude</div>
second one
<h2>First Header</h2>
<p>Paragraph <b>here</b>.</p>
<p>Another paragraph.</p>
third one
<h2 id="second">Second Header</h2>
<ul>
<li>One</li>
<li>Two</li>
</ul>
<blockquote>End quote!</blockquote>
You could try to cast the regex spell on that and try to, I don't know, split the string by the </h2>. But it's risky and error prone because (although a bit unlikely in this simple example) get caught up in <h2>...</h2> tags that are nested inside something else. Also, proper parsing almost always wins in the long run over regexes.
Use cheerio
This is how I solved it and hopefully A) you can copy and benefit, or B) someone tells me there's already a much better way.
What you do is walk the DOM root nodes, one by one, and keep filling a buffer and then yield individual new cheerio instances.
const html = `
<div>Prelude</div>
<h2>First Header</h2>
<p>Paragraph <b>here</b>.</p>
<p>Another paragraph.</p>
<!-- comment -->
<h2 id="second">Second Header</h2>
<ul>
<li>One</li>
<li>Two</li>
</ul>
<blockquote>End quote!</blockquote>
`;
// load the raw HTML
// it needs to all be wrapped in *one* big wrapper
const $ = cheerio.load(`<div id="_body">${html}</div>`);
// the end goal
const blocks = [];
// the buffer
const section = cheerio
.load("<div></div>", { decodeEntities: false })("div")
.eq(0);
const iterable = [...$("#_body")[0].childNodes];
let c = 0;
iterable.forEach(child => {
if (child.tagName === "h2") {
if (c) {
blocks.push(section.clone());
section.empty();
c = 0; // reset the counter
}
}
c++;
section.append(child);
});
if (c) {
// stragglers
blocks.push(section.clone());
}
// Test the result
const blocksAsStrings = blocks.map(block => block.html());
console.log(blocksAsStrings.length);
// 3
console.log(blocksAsStrings);
// [
// '\n<div>Prelude</div>\n\n',
// '<h2>First Header</h2>\n' +
// '<p>Paragraph <b>here</b>.</p>\n' +
// '<p>Another paragraph.</p>\n' +
// '<!-- comment -->\n' +
// '\n',
// '<h2 id="second">Second Header</h2>\n' +
// '<ul>\n' +
// ' <li>One</li>\n' +
// ' <li>Two</li>\n' +
// '</ul>\n' +
// '<blockquote>End quote!</blockquote>\n'
// ]
In this particular implementation the choice of splitting is by the every h2 tag. If you want to split by anything else, go ahead and adjust the conditional there where it's currently doing if (child.tagName === "h2") {.
Also, what you do with the blocks is up to you. Perhaps you need them as strings, then you use the blocks.map(block => block.html()). Otherwise, if it serves your needs they can remain as individual cheerio instances that you can do whatever with.
Avoid async when all you have is (SSD) disk I/O in NodeJS
October 24, 2019
1 comment Node, JavaScript
tl;dr; If you know that the only I/O you have is disk and the disk is SSD, then synchronous is probably more convenient, faster, and more memory lean.
I'm not a NodeJS expert so I could really do with some eyes on this.
There is little doubt in my mind that it's smart to use asynchronous ideas when your program has to wait for network I/O. Because network I/O is slow, it's better to let your program work on something else whilst waiting. But disk is actually fast. Especially if you have SSD disk.
The context
I'm working on a Node program that walks a large directory structure and looks for certain file patterns, reads those files, does some processing and then exits. It's a cli basically and it's supposed to work similar to jest where you tell it to go and process files and if everything worked, exit with 0 and if anything failed, exit with something >0. Also, it needs to be possible to run it so that it exits immediately on the first error encountered. This is similar to running jest --bail.
My program needs to process thousands of files and although there are thousands of files, they're all relatively small. So first I wrote a simple reference program: https://github.com/peterbe/megafileprocessing/blob/master/reference.js
What it does is that it walks a directory looking for certain .json files that have certain keys that it knows about. Then, just computes the size of the values and tallies that up. My real program will be very similar except it does a lot more with each .json file.
You run it like this:
▶ CHAOS_MONKEY=0.001 node reference.js ~/stumptown-content/kumadocs -q
Error: Chaos Monkey!
at processDoc (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:37:11)
at /Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:80:21
at Array.forEach (<anonymous>)
at main (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:78:9)
at Object.<anonymous> (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:99:20)
at Module._compile (internal/modules/cjs/loader.js:956:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:973:10)
at Module.load (internal/modules/cjs/loader.js:812:32)
at Function.Module._load (internal/modules/cjs/loader.js:724:14)
at Function.Module.runMain (internal/modules/cjs/loader.js:1025:10)
Total length for 4057 files is 153953645
1 files failed.
(The environment variable CHAOS_MONKEY=0.001 makes it so there's a 0.1% chance it throws an error)
It processed 4,057 files and one of those failed (thanks to the "chaos monkey").
In its current state that (on my MacBook) that takes about 1 second.
It's not perfect but it's a good skeleton. Everything is synchronous. E.g.
function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
files.forEach(file => {
try {
const total = processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
totalTotal += total;
} catch (err) {
if (bail) {
throw err;
} else {
console.error(err);
errors++;
}
}
});
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
}
return errors ? 1 : 0;
}
And inside the processDoc function it used const content = fs.readFileSync(fspath, "utf8");.
I/Os compared
@amejiarosario has a great blog post called "What every programmer should know about Synchronous vs. Asynchronous Code". In it, he has this great bar chart:
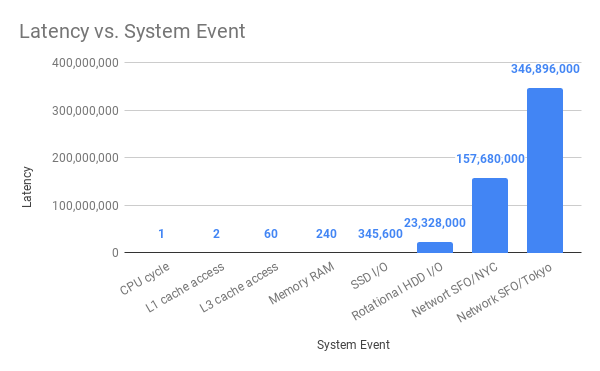
If you compare "SSD I/O" with "Network SFO/NCY" the difference is that SSD I/O is 456 times "faster" than SFO-to-NYC network I/O. I.e. the latency is 456 times less.
Another important aspect when processing lots of files is garbage collection. When running synchronous, it can garbage collect as soon as it has processed one file before moving on to the next. If it was asynchronous, as soon as it yields to move on to the next file, it might hold on to memory from the first file. Why does this matter? Because if the memory-usage when processing many files asynchronously bloat so hard that it actually crashes with an out-of-memory error. So what matters is avoiding that. It's OK if the program can use lots of memory if it needs to, but it's really bad if it crashes.
One way to measure this is to use /usr/bin/time -l (at least that's what it's called on macOS). For example:
▶ /usr/bin/time -l node reference.js ~/stumptown-content/kumadocs -q
Total length for 4057 files is 153970749
0.75 real 0.58 user 0.23 sys
57221120 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
64160 page reclaims
0 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
0 voluntary context switches
1074 involuntary context switches
Its maximum memory usage total was 57221120 bytes (55MB) in this example.
Introduce asynchronous file reading
Let's change the reference implementation to use const content = await fsPromises.readFile(fspath, "utf8");. We're still using files.forEach(file => { but within the loop the whole function is prefixed with async function main() { now. Like this:
async function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
let total;
for (let file of files) {
try {
total = await processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
totalTotal += total;
} catch (err) {
if (bail) {
throw err;
} else {
console.error(err);
errors++;
}
}
}
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
}
return errors ? 1 : 0;
}
Let's see how it works:
▶ /usr/bin/time -l node async1.js ~/stumptown-content/kumadocs -q
Total length for 4057 files is 153970749
1.31 real 1.01 user 0.49 sys
68898816 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
68107 page reclaims
0 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
0 voluntary context switches
62562 involuntary context switches
That means it maxed out at 68898816 bytes (65MB).
You can already see a difference. 0.79 seconds and 55MB for synchronous and 1.31 seconds and 65MB for asynchronous.
But to really measure this, I wrote a simple Python program that runs this repeatedly and reports a min/median on time and max on memory:
▶ python3 wrap_time.py /usr/bin/time -l node reference.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 0.74s WORST: 0.84s MEAN: 0.78s MEDIAN: 0.78s MAX MEMORY BEST: 53.5MB WORST: 55.3MB MEAN: 54.6MB MEDIAN: 54.8MB
And for the asynchronous version:
▶ python3 wrap_time.py /usr/bin/time -l node async1.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 1.28s WORST: 1.82s MEAN: 1.39s MEDIAN: 1.31s MAX MEMORY BEST: 65.4MB WORST: 67.7MB MEAN: 66.7MB MEDIAN: 66.9MB
Promise.all version
I don't know if the async1.js is realistic. More realistically you'll want to not wait for one file to be processed (asynchronously) but start them all at the same time. So I made a variation of the asynchronous version that looks like this instead:
async function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
let values;
values = await Promise.all(
files.map(async file => {
try {
total = await processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
return total;
} catch (err) {
if (bail) {
console.error(err);
process.exit(1);
} else {
console.error(err);
errors++;
}
}
})
);
totalTotal = values.filter(n => n).reduce((a, b) => a + b);
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
throw new Error("More than 0 errors");
}
}
You can see the whole file here: async2.js
The key difference is that it uses await Promise.all(files.map(...)) instead of for (let file of files) {.
Also, to accomplish the ability to bail on the first possible error it needs to use process.exit(1); within the callbacks. Not sure if that's right but from the outside, you get the desired effect as a cli program. Let's measure it too:
▶ python3 wrap_time.py /usr/bin/time -l node async2.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 1.44s WORST: 1.61s MEAN: 1.52s MEDIAN: 1.52s MAX MEMORY BEST: 434.0MB WORST: 460.2MB MEAN: 453.4MB MEDIAN: 456.4MB
Note how this uses almost 10x max. memory. That's dangerous if the processing is really memory hungry individually.
When asynchronous is right
In all of this, I'm assuming that the individual files are small. (Roughly, each file in my experiment is about 50KB)
What if the files it needs to read from disk are large?
As a simple experiment read /users/peterbe/Downloads/Keybase.dmg 20 times and just report its size:
for (let x = 0; x < 20; x++) {
fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
}
See the simple-async.js here. Basically it's this:
for (let x = 0; x < 20; x++) {
fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
}
Results are:
▶ python3 wrap_time.py /usr/bin/time -l node simple-async.js ... TIMES BEST: 0.84s WORST: 4.32s MEAN: 1.33s MEDIAN: 0.97s MAX MEMORY BEST: 1851.1MB WORST: 3079.3MB MEAN: 2956.3MB MEDIAN: 3079.1MB
And the equivalent synchronous simple-sync.js here.
for (let x = 0; x < 20; x++) {
const largeFile = fs.readFileSync("/users/peterbe/Downloads/Keybase.dmg");
console.log(`File size#${x}: ${Math.round(largeFile.length / 1e6)} MB`);
}
It performs like this:
▶ python3 wrap_time.py /usr/bin/time -l node simple-sync.js ... TIMES BEST: 1.97s WORST: 2.74s MEAN: 2.27s MEDIAN: 2.18s MAX MEMORY BEST: 1089.2MB WORST: 1089.7MB MEAN: 1089.5MB MEDIAN: 1089.5MB
So, almost 2x as slow but 3x as much max. memory.
Lastly, instead of an iterative loop, let's start 20 readers at the same time (simple-async2.js):
Promise.all(
[...Array(20).fill()].map((_, x) => {
return fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
})
);
And it performs like this:
▶ python3 wrap_time.py /usr/bin/time -l node simple-async2.js ... TIMES BEST: 0.86s WORST: 1.09s MEAN: 0.96s MEDIAN: 0.94s MAX MEMORY BEST: 3079.0MB WORST: 3079.4MB MEAN: 3079.2MB MEDIAN: 3079.2MB
So quite naturally, the same total time as the simple async version but uses 3x max. memory every time.
Ergonomics
I'm starting to get pretty comfortable with using promises and async/await. But I definitely feel more comfortable without. Synchronous programs read better from an ergonomics point of view. The async/await stuff is just Promises under the hood and it's definitely an improvement but the synchronous versions just have a simpler "feeling" to it.
Conclusion
I don't think it's a surprise that the overhead of event switching adds more time than its worth when the individual waits aren't too painful.
A major flaw with synchronous programs is that they rely on the assumption that there's no really slow I/O. So what if the program grows and morphs so that it someday does depend on network I/O then your synchronous program is "screwed" since an asynchronous version would run circles around it.
The general conclusion is; if you know that the only I/O you have is disk and the disk is SSD, then synchronous is probably more convenient, faster, and more memory lean.
Optimize DOM selector lookups by pre-warming by selectors' parents
February 11, 2019
0 comments Web development, Node, Web Performance, JavaScript
tl;dr; minimalcss 0.8.2 introduces a 20% post-processing optimization by lumping many CSS selectors to their parent CSS selectors as a pre-emptive cache.
In minimalcss the general core of it is that it downloads a DOM tree, as HTML, parses it and parses all the CSS stylesheets associated. These might be from <link ref="stylesheet"> or <style> tags.
Once the CSS stylesheets are turned into an AST it loops over each and every CSS selector and asks a simple question; "Does this CSS selector exist in the DOM?". The equivalent is to open your browser's Web Console and type:
>>> document.querySelectorAll('div.foo span.bar b').length > 0
false
For each of these lookups (which is done with cheerio by the way), minimalcss reduces the CSS, as an AST, and eventually spits the AST back out as a CSS string. The only problem is; it's slow. In the case of view-source:https://semantic-ui.com/ in the CSS it uses, there are 6,784 of them. What to do?
First of all, there isn't a lot you can do. This is the work that needs to be done. But one thing you can do is be smart about which selectors you look at and use a "decision cache" to pre-emptively draw conclusions. So, if this is what you have to check:
#example .alternate.stripe#example .theming.stripe#example .solid .column p b#example .solid .column p
As you process the first one you extract that the parent CSS selector is #example and if that doesn't exist in the DOM, you can efficiently draw conclusion about all preceeding selectors that all start with #example .... Granted, if they call exist you will pay a penalty of doing an extra lookup. But that's the trade-off that this optimization is worth.
Check out the comments where I tested a bloated page that uses Semantic-UI before and after. Instead of doing 3,285 of these document.querySelector(selector) calls, it's now able too come to the exact same conclusion with just 1,563 lookups.
Sadly, the majority of the time spent processing lies in network I/O and other overheads but this work did reduce something that used to take 6.3s (median) too 5.1s (median).
Now using minimalcss
March 12, 2018
0 comments Python, Web development, JavaScript, Node
tl;dr; minimalcss is much better than mincss to slew out the minimal CSS your page needs to render. More accurate and more powerful features. This site now uses minimalcss in inline the minimum CSS needed to render the page.
I started minimalcss back in August 2017 and its goal was ultimately to replace mincss.
The major difference between minimalcss and mincss isn't that one is Node and one is Python, but that minimalcss is based on a full headless browser to handle all the CSS downloading and the proper rendering of the DOM. The other major difference is that mincss was based in regular expressions to analyze the CSS and minimalcss is based on proper abstract syntax tree ("AST") implemented by csso.
Because minimalcss is AST based, it can do a lot more. Smarter. For example, it's able to analyze the CSS to correctly and confidently figure out if any/which keyframe animations and font-face at-rules are actually needed.
Also, because minimalcss is based on csso, when it minifies the CSS it's able to restructure the CSS in a safe and smart way. I.e. p { color: blue; } h2 { color: blue; } becomes p,h2{color:blue}.
So, now I use minimalcss here on this blog. The pages are rendered in Django and a piece of middleware sniffs all outgoing HTML responses and depending on the right conditions it dumps the HTML as a file on disk as path/in/url/index.html. Then, that newly created file is sent to a background worker in Celery which starts post-processing it. Every index.html file is accompanied with the full absolute URL that it belongs to and that's the URL that gets sent to minimalcss which returns the absolute minimal CSS the page needs to load and lastly, a piece of Python script basically does something like this:
From...
<!-- before -->
<link rel="stylesheet" href="/file.css"/>
To...
<!-- after -->
<noscript><link rel="stylesheet" href="/file.css"/></noscript>
<style> ... /* minimal CSS selectors for rendering from /file.css */ ... </style>
There is also a new JavaScript dependency which is the cssrelpreload.js from the loadCSS project. So all the full (original) CSS is still downloaded and inserted into the CSSOM but it happens much later which ultimately means the page can be rendered and useful much sooner than if we'd have to wait to download and parse all of the .css URLs.
I can go into more details if there's interest and others want to do this too. Because this site is all Python and minimalcss is all Node, the integration is done over HTTP on localhost with minimalcss-server.
The results
Unfortunately, this change was mixed in with other smaller optimizations that makes the comparison unfair. (Hey! my personal blog is just a side-project after all). But I downloaded a file before and after the upgrade and compared:
▶ ls -lh *.html
-rw-r--r-- 1 peterbe wheel 19K Mar 7 13:22 after.html
-rw-r--r-- 1 peterbe wheel 96K Mar 7 13:21 before.html
If I extract out the inline style block from both pages and compare it looks like this:
https://gist.github.com/peterbe/fc2fdddd5721fb35a99dc1a50c2b5311
So, downloading the initial HTML document is now 19KB instead of previous 96KB. And visually there's absolutely no difference.
Granted, in the after.html version, a piece of JavaScript kicks in and downloads /static/css/base.min.91f6fc577a60.css and /static/css/base-dynamic.min.e335b9bfa0b1.css from the CDN. So you have to download these too:
▶ ls -lh *.css.gz
-rw-r--r-- 1 peterbe wheel 5.0K Mar 7 10:24 base-dynamic.min.e335b9bfa0b1.css.gz
-rw-r--r-- 1 peterbe wheel 95K Mar 7 10:24 base.min.91f6fc577a60.css.gz
The reason the difference appears to be huge is because I changed a couple of other things around the same time. Sorry. For example, certain DOM nodes were rendered as HTML but made hidden until some jQuery script made it not hidden anymore. For example, the "dimmer" effect over a comment textarea after you hit the submit button. Now, I've changed the jQuery code to build up the DOM when it needs it rather than relying on it being there (hidden). This means that certain base64 embedded font-faces are no longer needed in the minimal CSS payload.
Why this approach is better
So the old approach was to run mincss on the HTML and inject that as an inline style block and throw away the original (relevant) <link rel="stylesheet" href="..."> tags.
That had the annoying drawback that there was CSS in the stylesheets that I knew was going to be needed by some XHR or JavaScript later. For example, if you post a comment some jQuery code changes the DOM and that new DOM needs these CSS selectors later. So I had to do things like this:
.project a.perm { /* no mincss */
font-size: 0.7em;
padding-left: 8px;
}
.project a.perm:link { /* no mincss */
color: rgb(151,151,151);
}
.project a.perm:hover { /* no mincss */
color: rgb(51,51,51);
}
This was to inform mincss to leave those untouched even though no DOM node uses them right now. With minimalcss this is no longer needed.
What's next?
Keep working on minimalcss and make it even better.
Also, the scripting I used to modify the HTML file is a hack and should probably be put into the minimalcss project.
Last but not least, every time I put in some effort to web performance optimize my blog pages my Google ranking goes up and I usually see an increase in Google referrals in my Google Analytics because it's pretty obvious that Google loves fast sites. So I'm optimistically waiting for that effect.
minimalcss 0.6.2 now strips all unused font faces
January 22, 2018
0 comments Web development, JavaScript, Node
minimalcss is a Node API and cli app to analyze the minimal CSS needed for initial load. One of it's killer features is that all CSS parsing is done the "proper way". Meaning, it's reduced down to an AST that can be iterated over, mutated and serialized back to CSS as a string.
Thanks to this, together with my contributors @stereobooster and @lahmatiy, minimalcss can now figure out which @font-face rules are redundant and can be "safely" removed. It can make a big difference on web performance. Either because it prevents expensive network requests of downloading some https://fonts.gstatic.com/s/lato/v14/hash.woff2 or downloading base64 encoded fonts.
For example, this very blog uses Semantic UI which is a wonderful CSS framework. But it's quite expensive and contains a bunch of base64 encoded fonts. The Ratings module uses a @font-face rule that weighes about 15KB.
Sure, you don't have to download and insert semanticui.min.css in your HTML but it's just sooo convenient. Especially when there's tools like minimalcss that allows you to be "lazy" but get that perfect first load web performance thing.
So, the CSS when doing a search looks like this:
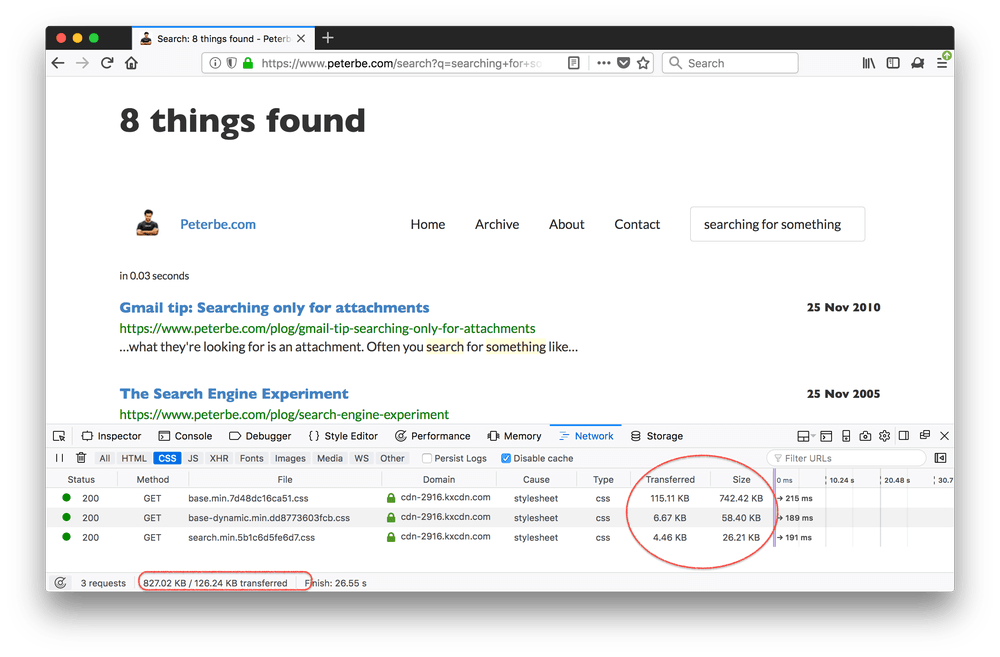
126KB of CSS (gzipped) transferred and 827KB of CSS parsed.
Let's run this through minimalcss instead:
$ minimalcss.js --verbose -o /tmp/peterbe.search.css "https://www.peterbe.com/search?q=searching+for+something"
$ ls -lh /tmp/peterbe.search.css
-rw-r--r-- 1 peterbe wheel 27K Jan 22 09:59 /tmp/peterbe.search.css
$ head -n 14 /tmp/peterbe.search.css
/*
Generated 2018-01-22T14:59:05.871Z by minimalcss.
Took 4.43 seconds to generate 26.85 KB of CSS.
Based on 3 stylesheets totalling 827.01 KB.
Options: {
"urls": [
"https://www.peterbe.com/search?q=searching+for+something"
],
"debug": false,
"loadimages": false,
"withoutjavascript": false,
"viewport": null
}
*/
And let's simulate it being gzipped:
$ gzip /tmp/peterbe.search.css $ ls -lh /tmp/peterbe.search.css.gz -rw-r--r-- 1 peterbe wheel 6.0K Jan 22 09:59 /tmp/peterbe.search.css.gz
Wow! Instead of downloading 27KB you only need 6KB. CSS parsing isn't as expensive as JavaScript parsing but it's nevertheless a saving of 827KB - 27KB = 800KB of CSS for the browser to not have to worry about. That's awesome!
By the way, the produced minimal CSS contains a lot of license preamble as left over from the fact that the semanticui.min.css is made up of components. See the gist itself.
Out of the total size of 27KB (uncompressed) 8KB is just the license preambles. minimalcss does not attempt to touch that when it minifies but you could easily add your own little tooling to re-write it, since there's a lot of repetition and save another ~7KB. However, all that repetition compresses well so it might not be worth it.