tl;dr; minimalcss is much better than mincss to slew out the minimal CSS your page needs to render. More accurate and more powerful features. This site now uses minimalcss in inline the minimum CSS needed to render the page.
I started minimalcss back in August 2017 and its goal was ultimately to replace mincss.
The major difference between minimalcss and mincss isn't that one is Node and one is Python, but that minimalcss is based on a full headless browser to handle all the CSS downloading and the proper rendering of the DOM. The other major difference is that mincss was based in regular expressions to analyze the CSS and minimalcss is based on proper abstract syntax tree ("AST") implemented by csso.
Because minimalcss is AST based, it can do a lot more. Smarter. For example, it's able to analyze the CSS to correctly and confidently figure out if any/which keyframe animations and font-face at-rules are actually needed.
Also, because minimalcss is based on csso, when it minifies the CSS it's able to restructure the CSS in a safe and smart way. I.e. p { color: blue; } h2 { color: blue; } becomes p,h2{color:blue}.
So, now I use minimalcss here on this blog. The pages are rendered in Django and a piece of middleware sniffs all outgoing HTML responses and depending on the right conditions it dumps the HTML as a file on disk as path/in/url/index.html. Then, that newly created file is sent to a background worker in Celery which starts post-processing it. Every index.html file is accompanied with the full absolute URL that it belongs to and that's the URL that gets sent to minimalcss which returns the absolute minimal CSS the page needs to load and lastly, a piece of Python script basically does something like this:
From...
<!-- before -->
<link rel="stylesheet" href="/file.css"/>
To...
<!-- after -->
<noscript><link rel="stylesheet" href="/file.css"/></noscript>
<style> ... /* minimal CSS selectors for rendering from /file.css */ ... </style>
There is also a new JavaScript dependency which is the cssrelpreload.js from the loadCSS project. So all the full (original) CSS is still downloaded and inserted into the CSSOM but it happens much later which ultimately means the page can be rendered and useful much sooner than if we'd have to wait to download and parse all of the .css URLs.
I can go into more details if there's interest and others want to do this too. Because this site is all Python and minimalcss is all Node, the integration is done over HTTP on localhost with minimalcss-server.
The results
Unfortunately, this change was mixed in with other smaller optimizations that makes the comparison unfair. (Hey! my personal blog is just a side-project after all). But I downloaded a file before and after the upgrade and compared:
▶ ls -lh *.html
-rw-r--r-- 1 peterbe wheel 19K Mar 7 13:22 after.html
-rw-r--r-- 1 peterbe wheel 96K Mar 7 13:21 before.html
If I extract out the inline style block from both pages and compare it looks like this:
https://gist.github.com/peterbe/fc2fdddd5721fb35a99dc1a50c2b5311
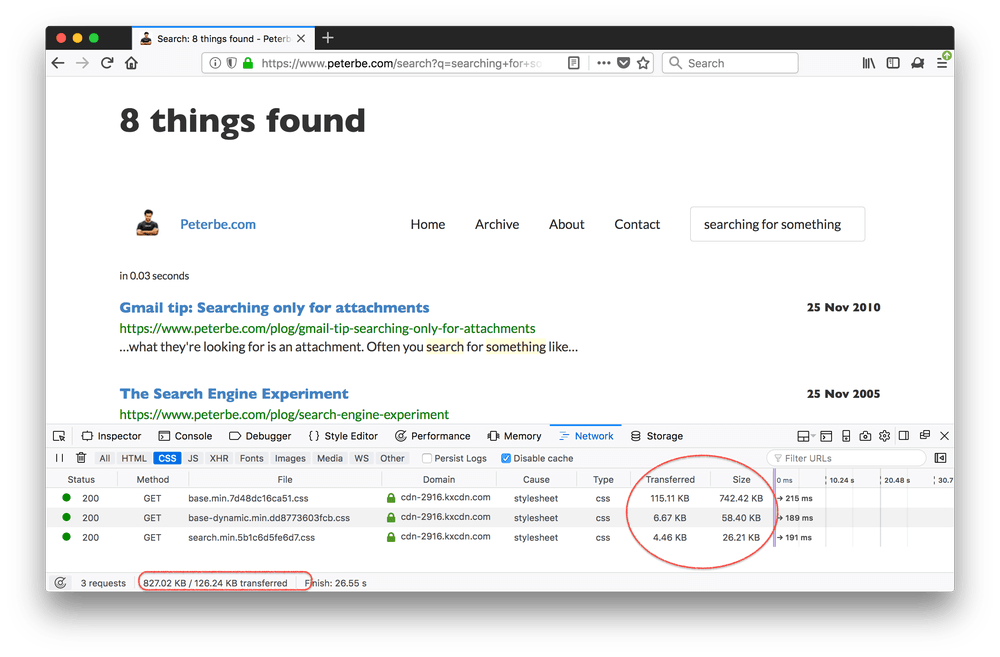
So, downloading the initial HTML document is now 19KB instead of previous 96KB. And visually there's absolutely no difference.
Granted, in the after.html version, a piece of JavaScript kicks in and downloads /static/css/base.min.91f6fc577a60.css and /static/css/base-dynamic.min.e335b9bfa0b1.css from the CDN. So you have to download these too:
▶ ls -lh *.css.gz
-rw-r--r-- 1 peterbe wheel 5.0K Mar 7 10:24 base-dynamic.min.e335b9bfa0b1.css.gz
-rw-r--r-- 1 peterbe wheel 95K Mar 7 10:24 base.min.91f6fc577a60.css.gz
The reason the difference appears to be huge is because I changed a couple of other things around the same time. Sorry. For example, certain DOM nodes were rendered as HTML but made hidden until some jQuery script made it not hidden anymore. For example, the "dimmer" effect over a comment textarea after you hit the submit button. Now, I've changed the jQuery code to build up the DOM when it needs it rather than relying on it being there (hidden). This means that certain base64 embedded font-faces are no longer needed in the minimal CSS payload.
Why this approach is better
So the old approach was to run mincss on the HTML and inject that as an inline style block and throw away the original (relevant) <link rel="stylesheet" href="..."> tags.
That had the annoying drawback that there was CSS in the stylesheets that I knew was going to be needed by some XHR or JavaScript later. For example, if you post a comment some jQuery code changes the DOM and that new DOM needs these CSS selectors later. So I had to do things like this:
.project a.perm { /* no mincss */
font-size: 0.7em;
padding-left: 8px;
}
.project a.perm:link { /* no mincss */
color: rgb(151,151,151);
}
.project a.perm:hover { /* no mincss */
color: rgb(51,51,51);
}
This was to inform mincss to leave those untouched even though no DOM node uses them right now. With minimalcss this is no longer needed.
What's next?
Keep working on minimalcss and make it even better.
Also, the scripting I used to modify the HTML file is a hack and should probably be put into the minimalcss project.
Last but not least, every time I put in some effort to web performance optimize my blog pages my Google ranking goes up and I usually see an increase in Google referrals in my Google Analytics because it's pretty obvious that Google loves fast sites. So I'm optimistically waiting for that effect.